RegulAgro – Assistant IA réglementaire agrochimique par fine-tuning
Contexte et problème
Les opérateurs du secteur agrochimique (fabricants, distributeurs, conseillers agricoles) font face à une réglementation dense, technique et en évolution permanente : Règlement (CE) n°1107/2009, LMR (n°396/2005), biostimulants (UE 2019/1009), procédures ANSES, liste biocontrôle (Art. L253-6 CRPM)…
L’accès à une expertise réglementaire senior représente un investissement significatif pour obtenir des réponses à des questions critiques telles que :
- “Mon produit à base de Trichoderma harzianum doit-il être enregistré comme PPP ou biostimulant ?”
- “Quelle LMR s’applique si aucune valeur spécifique n’est fixée dans le Règlement 396/2005 ?”
- “Quels avantages concrets donne l’inscription sur la liste nationale des produits de biocontrôle ?”
Les modèles d’IA classiques sont trop généralistes pour apporter des réponses fiables. Par manque de spécialisation, ils hallucinent : confusion des catégories, invention d’articles de loi ou ignorance des mises à jour récentes. Ce n’est pas un manque de puissance, mais un manque de précision métier.
L’objectif de ce projet est de développer un modèle expert via le fine-tuning d’un modèle open-weights, afin de surpasser systématiquement les modèles généralistes sur la conformité, l’autorisation et le statut des substances en droit français et européen.
Ce projet s’adresse spécifiquement aux entreprises de recherche et startups en agrochimie, leur offrant un outil capable de traiter le corpus réglementaire sans les risques d’interprétation erronée propres aux IA non spécialisées.

Stratégies d’augmentation de connaissances
Face à un modèle généraliste, deux stratégies permettent d’injecter des connaissances spécifiques : le RAG (Retrieval-Augmented Generation) et le fine-tuning.
- Le RAG ne modifie pas le modèle, mais lui donne accès temporairement à une base documentaire au moment de la requête. Les passages pertinents sont retrouvés par recherche vectorielle et injectés dans le contexte du prompt.
- Le fine-tuning intègre les connaissances dans les poids du modèle via un entraînement supplémentaire. Le modèle est alors modifié et les informations des documents sont assimilées définitevement par ce dernier.
Le fine-tuning a été le choix retenu dans ce projet pour deux raisons principales. Tout d’abord, l’objectif de ce projet était de démontrer qu’un modèle pouvait mémoriser le droit français du domaine de l’agrochimie, et pas seulement le retrouver : un modèle fine-tuné sait que “l’Art. 53 du Règl. 1107/2009 autorise une AMM d’urgence de 120 jours” sans qu’on le lui rappelle à chaque requête.
Le RAG est quant-à lui tributaire de la qualité du stockage et de la récupération : si le bon document n’est pas retrouvé, le modèle hallucine quand même. Sur des questions ultra-précises (numéros d’articles, dates d’entrée en vigueur, LMR chiffrées), ce risque n’est pas acceptable dans un contexte de conformité réglementaire.
Enfin, ce projet fait partie du projet Nexus, visant à développer une plateforme complète d’assistants personnels IA. Dans ce contexte, le développement d’un agent IA autonome et robuste, spécialisé en legislation française, nécessite un modèle fine-tuné.
RAG (Retrieval-Augmented Generation)
Le RAG ne modifie pas le modèle mais lui donne accès à une base documentaire au moment de la requête : les passages pertinents sont retrouvés par recherche vectorielle et injectés dans le contexte avant la génération.
Forces :
- Données à jour en temps réel (modifier la base, pas le modèle)
- Traçabilité des sources (on peut citer le document exact)
- Fonctionne sans GPU dédié, avec l’API d’un fournisseur
- Déployable en quelques jours
Limites :
- Fenêtre de contexte limitée : on ne peut pas tout injecter
- Qualité tributaire du retrieval : si le bon document n’est pas retrouvé, le modèle hallucine quand même
- Le modèle doit interpréter les documents : il peut se tromper sur des subtilités réglementaires
- Latence et coût par requête (embedding + LLM call)
Fine-tuning
Le fine-tuning intègre les connaissances dans les poids du modèle.
Forces :
- Connaissances profondément intégrées : le modèle raisonne avec, pas à partir de
- Pas de retrieval à rater : la connaissance est toujours là
- Latence plus faible, déployable en local
- Style et format de réponse parfaitement contrôlés
Limites :
- Requiert un dataset de qualité (plusieurs milliers de paires minimum)
- Temps et ressources d’entraînement
- Connaissances figées à la date du dataset : nécessite des re-runs pour les mises à jour
- Risque de catastrophic forgetting si mal configuré

Règle empirique simple pour choisir :
- Données changent souvent + sources à citer → RAG
- Style/comportement + domaine ultra-spécialisé → Fine-tuning
- Cas complexe avec forte valeur métier → Les deux (RAG + FT)
Dans les domaines où la précision de citation est critique (droit, médecine, conformité réglementaire), le fine-tuning seul ne suffit souvent pas : un modèle fine-tuné qui a internalisé les articles peut encore confondre des dates ou des numéros. Le combo RAG + fine-tuning est la cible de production sérieuse.
Pour aller plus loin sur les stratégies RAG avancées, qui ne seront pas traitées dans cet article, voir le projet SciGraphRAG sur la génération de graphes de connaissances depuis un corpus de texte et leur exploitation dans un contexte réél via un LLM.
Objectif et axe de différenciation
Créer un assistant qui, sur les 10 questions de démonstration, cite systématiquement le bon règlement, le bon article, et la bonne date. Le modèle de base hallucine ou répond de manière trop vague pour être utile dans ces exemples.
L’axe de différenciation est mesurable et démontrable selon différents critères :
| Critère | Modèle de base | RegulAgro (cible) |
|---|---|---|
| Citation d’un numéro de règlement | Aléatoire | Systématique |
| Citation d’un article précis | Rare | Fréquente |
| Confusion biostimulant / PPP | Fréquente | Absente |
| LMR par défaut chiffrée | Ignorée | Citée (0,01 mg/kg, Art. 18§1b) |
| Procédure AMM d’urgence | Vague | Art. 53, 120 jours, ANSES |
Stack technique
Modèle de base : Qwen3-14B — fort raisonnement structuré, multilingue FR/EN
Quantization : Q5_K_M (GGUF) pour l'inférence baseline via Ollama
Fine-tuning : QLoRA 4-bit NF4 via Unsloth + TRL SFTTrainer
GPU : 2× NVIDIA RTX 5070 Ti (16 Go VRAM chacune)
LoRA rank : 64 (domaine ultra-spécialisé : mémorisation précise des articles)
Données : EUR-Lex (HTML), ANSES open data, EFSA, Légifrance
Pourquoi Qwen3-14B ? Parmi les modèles open-weight dans cette gamme de taille, Qwen3 présente les meilleures performances en raisonnement structuré et en français réglementaire.
La version 14B tient en 4-bit sur un seul GPU 16 Go pour l’inférence, et sur deux GPUs en QLoRA pour l’entraînement.
Le récent Qwen3.5 est un VLM et nécessite un pipeline de fine-tuning adapté. L’objectif de ce projet est de concevoir un pipeline au sien duquel le modèle de bas eutilisé est facilement interchangeable.
Pourquoi QLoRA et pas un full fine-tuning ? Le full fine-tuning d’un 14B nécessiterait ~80-100 Go de VRAM. QLoRA (4-bit NF4 + matrices LoRA rank 64) ramène ce besoin à ~14-16 Go par GPU, avec une dégradation de qualité négligeable sur les tâches de spécialisation domaine. C’est le standard industriel pour les modèles 7B-70B.
La totalité du projet a été réalisé sur infrastructure de calcul personnelle, en local pour simuler des conditions nécessitant une confidentialité end-to-end des données utilisées. QLoRa permet dans ce cas présent un fine-tuning rapide et efficace.
Stratégie de données
Sources et acquisition
Un pipeline complet de récupération des données a été mis au point. Des textes réglementaires relatifs au domaine étudié (i.e. l’agrochimie dans cet exemple) ont été récupérés via plusieurs plateformes gouvernementales libre d’accès :
| Source | Contenu | Méthode |
|---|---|---|
| EUR-Lex | Textes intégraux | Scraping avec Selenium Chrome headless (AWS WAF Bot Control) |
| ANSES / data.gouv.fr | Registre AMM | Requests direct (open data) |
| Légifrance | Textes législatifs | API gouvernementale |
L’approche adoptée est un pipeline adaptable à d’autres domaines législatifs, pour pouvoir l’exploiter pour le fine-tune d’autres modèles avec le minimum d’adaptation de scripts.
Ci-après des exemples de la couverture :
Règlements EUR-Lex :
- Règl. (CE) n°1107/2009 — PPP (mise sur le marché)
- Règl. (CE) n°396/2005 — LMR pesticides
- Règl. (CE) n°540/2011 — substances actives approuvées
- Règl. (UE) n°2019/1009 — fertilisants et biostimulants
- Règl. (CE) n°1907/2006 — REACH
- Règl. (CE) n°1272/2008 — CLP
- Directive 2009/128/CE — usage durable (Écophyto)
- Règl. (UE) n°2021/1165 — agriculture biologique
Extraits législatifs :
- L230-5-1 : Restauration collective et objectifs de 50% de produits durables/bio (issu du règlement 834/2007).
- L253-1 à L253-17 : Cadre fondamental de la mise sur le marché des produits phytopharmaceutiques.
- R253-6 : Précision sur les compétences du ministre chargé de l’agriculture pour les AMM d’urgence (Art. 53 du Règl. 1107/2009).
- R253-7 : Procédures de transfert d’autorisation et changements de dénomination commerciale.
- L255-1 à L255-11 : Régime spécifique aux matières fertilisantes, adjuvants et supports de culture (indispensable pour distinguer les PPP des biostimulants).
Génération du dataset par LLM
Les textes bruts sont découpés en chunks de 1 500 caractères (avec chevauchement de 200), puis soumis à un LLM local (Qwen3-14B via Ollama) pour générer des paires questions-réponses (Q&A) en français réglementaire.
Chaque chunk reçoit la référence explicite du règlement source pour que le LLM inclue systématiquement la citation dans sa réponse.
Les paires sont ensuite filtrées dans une boucle de validation :
- Longueur minimale de réponse (120 caractères)
- Présence d’au moins une citation réglementaire (regex : n°XXX/XXXX ou article X)
- Déduplication exacte + quasi-déduplication par préfixe de 80 caractères
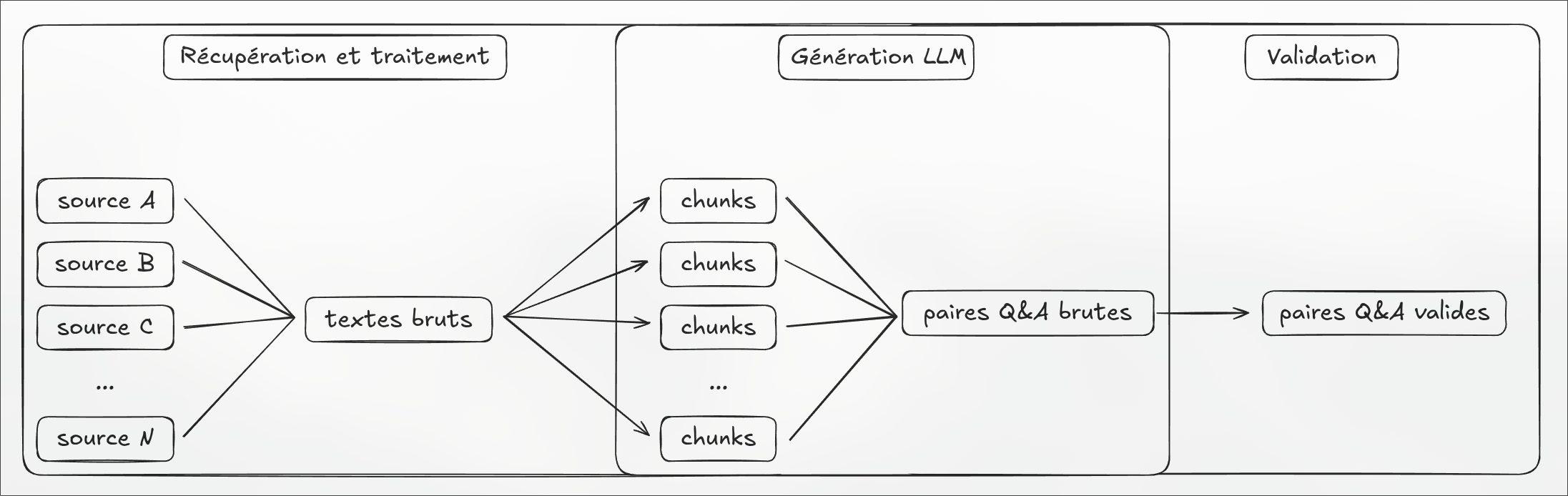
À l’issue de ce pipeline de traitement des données, les paires Q&A couvrent largement les domaines d’études avec des questions complètes et non-dupliquées.
Volume du dataset :
| Catégorie | Procédures & AMM | Statuts substances actives | Textes réglementaires | Biostimulant / Biocontrôle | Cas pratiques terrain | Total |
|---|---|---|---|---|---|---|
| Paires | 9 000 | 8 500 | 4 000 | 2 000 | 1 500 | ≥ 25 000 |
Fine-tune de Qwen3 : QLoRA + Unsloth
Le fine-tuning d’un modèle 14B en full precision nécessiterait ~80–100 Go de VRAM (poids + gradients + états d’optimiseur).
La solution retenue est QLoRA (Dettmers et al., 2023) : le modèle de base est compressé en 4-bit NF4 (NormalFloat — grille de quantization optimisée pour les distributions normales des poids de LLM), ce qui ramène les ~28 Go de Qwen3-14B à ~7 Go.
Sur ce modèle gelé, on n’entraîne que de petites matrices LoRA de rang 64 injectées dans les 7 projections de chaque bloc transformer (Q/K/V/O pour l’attention, gate/up/down pour le MLP), représentant 1,71% des paramètres totaux (256M entraînables sur 15B).
Le choix du rang 64 est intentionnel : pour mémoriser des numéros d’articles exacts, des dates et des LMR chiffrées, un rang faible (8–16) ne suffit pas. Le scaling alpha=128 (alpha/r = 2.0) est la convention standard pour un apprentissage stable.
Le framework Unsloth optimise l’empreinte mémoire via des kernels Triton fusionnés et un gradient checkpointing sélectif (seules les couches MLP les plus coûteuses sont recomputées).
Résultat mesuré : ~12s/step sur RTX 5070 Ti 16 Go, contre ~18–22s estimés avec transformers standard (soit ~40% plus rapide).
# Chargement du modèle de base quantizé + injection des adaptateurs LoRA
from unsloth import FastLanguageModel
import torch
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="Qwen/Qwen3-14B", # le modèle que vous souhaitez fine-tuner
max_seq_length=4096, # context window
dtype=torch.bfloat16, # Format de précision (directement correlé à la VRAM disponible!)
load_in_4bit=True, # Quantisation ! Paramètre important pour réduire l'empreinte en VRAM
device_map="sequential", # permet de faire déborder les poids du modèle sur plusieurs GPUs (si c'est le cas, bravo pour votre config !)
)
model = FastLanguageModel.get_peft_model(
model,
r=64, # Rang LoRA. Ici élevé pour mémorisation précise d'articles
lora_alpha=128, # Facteur de scaling (alpha/r = 2.0 usuellement). Régit l'importance donnée aux nouvelles informations
lora_dropout=0.05, # Régularisation deep learning classique
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"], # Couches ciblées, ici large pour capturer l'essence sémantique du corpus
use_gradient_checkpointing="unsloth", # La raison pourquoi on utilise Unsloth est ici ! Économie importante de la VRAM
)
# Le tokenizer applique le chat template Qwen3
def formatting_func(examples):
msgs = examples["messages"]
if msgs and isinstance(msgs[0], dict):
msgs = [msgs]
return [
tokenizer.apply_chat_template(m, tokenize=False, add_generation_prompt=False)
for m in msgs
]
L’entraînement utilise le SFTTrainer de la bibliothèque TRL avec un batch effectif de 16, un learning rate de 1,5×10⁻⁴ avec scheduler cosine, sur 4 epochs (soit ~1 188 steps pour 16 761 exemples d’entraînement). Les checkpoints sont sauvegardés toutes les 250 steps et la loss de validation est monitorée en continu via W&B.
À titre de référence, cette étape de réentrainement à duré 8 heures sur une RTX 5070Ti. Des essais de model parallelism ont été réalisés (en splittant le modèle sur deux GPUs), mais le bottleneck du à la vitesse de transfert de données entre les bus PCI-E réduisant légèrement les performences. L’entrainement a donc été réalisé sur une seule GPU, le modèle de base utilisé étant assez compact pour tenir dans 16Gb de VRAM. Il est cependant intéressant de noter que cette stratégie de parallélisation pourra être exploitée dans le cas de modèle plus lourds.
Benchmark et évaluation
Questions de démonstration
Dix questions ont été définies comme référence pour évaluer la capacité du modèle à citer correctement les règlements et articles pertinents, sans halluciner ni confondre les catégories réglementaires.
Ces résultats préliminaires seront à compléter par une évaluation plus large sur un ensemble plus conséquent (augmentation du dataset d’évaluation d’un facteur 100) pour tester la cohérence du modèle fine-tuné sur un échantillon plus large, et ainsi obtenir des résultats quantitatifs plutôt que qualitatifs.
| ID | Catégorie | Question | Signal attendu |
|---|---|---|---|
| D001 | AMM d’urgence | Quelles sont les conditions pour obtenir une AMM d’urgence en France et quel est l’article applicable ? | Art. 53 Règl. 1107/2009, Art. L253-4 CRPM, 120 jours, ANSES, risque phytosanitaire imprévu. |
| D002 | Statut substance | Le diméthoate est-il encore autorisé en France ? Depuis quand et pourquoi ? | Non renouvelé (2016), Règl. 2019/1143, perturbateur endocrinien, retrait des AMM. |
| D003 | Biostimulant vs PPP | Un Trichoderma harzianum utilisé contre Botrytis cinerea doit-il être enregistré comme PPP ou biostimulant ? | PPP, Art. 2§1 Règl. 1107/2009, action contre organisme nuisible, Règl. 2019/1009 inapplicable. |
| D004 | Biocontrôle | Quels avantages concrets donne l’inscription sur la liste nationale des produits de biocontrôle ? | Art. L253-6 CRPM, délais réduits, Loi EGAlim, dispense d’agrément, réduction redevance pour pollutions diffuses. |
| D005 | LMR | Quelle LMR s’applique par défaut si aucune LMR spécifique n’est fixée dans le Règlement 396/2005 ? | 0,01 mg/kg, Art. 18§1b Règl. 396/2005, limite de quantification analytique. |
| D006 | P.E. | Pourquoi le Chlorpyrifos-méthyl a-t-il été retiré du marché européen ? | Règl. exécution 2020/18, neurotoxicité développementale, critères perturbateur endocrinien, Art. 4 Règl. 1107/2009. |
| D007 | Procédure | Un fabricant espagnol dont le PPP est autorisé en Espagne peut-il demander une AMM simplifiée en France ? | Art. 40 Règl. 1107/2009, zone Sud, reconnaissance mutuelle, État membre de référence, ANSES. |
| D008 | Adjuvants | Un adjuvant à base d’huile de colza doit-il obtenir une AMM en France ? Quelle est la base légale ? | Art. L253-1 CRPM, Décret 2016-623, AMM adjuvant, évaluation ANSES, mention sur e-phy. |
| D009 | Bio | Quelles substances actives sont autorisées en agriculture biologique pour la protection contre les insectes ? | Règl. 2021/1165, Annexe I, substances d’origine naturelle (pyrèthre, spinosad), azadirachtine. |
| D010 | Écophyto | Qu’est-ce que le NODU et comment est-il calculé dans le cadre du plan Écophyto ? | Nombre de Doses Unités, Directive 2009/128, indicateur de pression, calculé sur les doses maximales autorisées. |
Résultats
Les tableaux présenté ci-après ont été réalisé via une procédure d’évaluation LLM-as-a-judge, où un modèle de jugement (ici Gemini-3.5-Pro) évalue la pertinence, la précision et la complétude des réponses générées par le modèle fine-tuné par rapport à la baseline. Ces résultats seront ultérieurement évalués avec la librairie RAGAS, spécialisé dans cette méthodologie de LLM-as-a-judge (Es S. et al., arXiv:2309.15217).
Les scores sont basés sur des critères objectifs tels que la présence de citations réglementaires correctes, la précision des informations fournies, et l’absence d’hallucinations.
Évaluation qualitative globale
L’analyse qualitative met en évidence une rupture nette entre le modèle de base et la version fine-tuned.
| Métrique / Comportement | Baseline (Qwen3-14B) | Fine-tune (RegulAgro) |
|---|---|---|
| Compréhension du sigle métier (ex: PPP, LMR) | Défaillante. Invente des significations hors sujet (ex: LMR = Ligne directrice pour transport de marchandises ; PPP = Permiso de Plazas de Medicamentos). | Parfaite. Identifie immédiatement “Produit Phytopharmaceutique” et “Limite Maximale de Résidus”. |
| Ancrage juridique | Erroné. Dérive systématique vers le Code de la Santé Publique (pharmacie humaine). | Précis. Mobilise le Code Rural et de la Pêche Maritime (CRPM) et les Règlements CE adéquats. |
| Citations d’Articles/Règlements | Souvent inventées ou inadaptées au contexte agricole. | Systématiques, précises (art. L253-12, Règl. 1107/2009) et vérifiables. |
La Baseline (Qwen3-14B) présente une pathologie de génération caractéristique : un volume de texte disproportionné pour une densité d’information quasi nulle. Ce phénomène s’explique par des boucles de répétition et une incapacité à clore la réponse face à des questions précises nécessitant des informations exactes et sourcées.
À l’inverse, le fine-tune démontre une maîtrise complète du périmètre réglementaire sur les trois axes évalués : identification immédiate des sigles métier, ancrage systématique dans le Code Rural et les Règlements CE applicables, et production de citations vérifiables — là où la baseline produit des références inexactes ou hors domaine.
Analyse qualitative par axe
Au-delà des métriques brutes, l’examen qualitatif révèle une transformation de la posture sémantique du modèle.
La baseline souffre d’un défaut de désambiguïsation de domaine : elle traite les questions phytosanitaires sous l’angle du droit médical ou des droits de l’homme, faute d’avoir ancré ses connaissances dans le Code Rural (voir D001 : le modèle cite l’Art. L5121-10 du Code de la santé publique pour une question sur les AMM phytopharmaceutiques).
| Axe d’Évaluation | Baseline | Fine-tune (RegulAgro) |
|---|---|---|
| Cadrage du domaine | Inutilisable : Traite les questions phytosanitaires sous l’angle du droit médical (médicaments humains, cancer) ou de la logistique (transport routier de matières dangereuses). | Excellent. Identifie immédiatement le contexte agrochimique et ancre la réponse dans les bonnes autorités (ANSES, EFSA). |
| Précision juridique | Faible et trompeuse : Invente des règlements (ex: “Règlement (UE) 2018/603” pour les PPP) ou applique des lois de médecine humaine à l’agriculture. | Élevée. Cite les bases légales exactes (Règl. 1107/2009, 396/2005, 2019/1009) et les numéros d’articles pertinents du Code Rural. |
| Hallucinations | Structurelles : Comble ses lacunes par des inventions sémantiques totales (ex: réinvente le terme LMR de toutes pièces). | Résolues. Le modèle s’en tient aux faits réglementaires. |
| Structure de réponse | Verbeuse, avec des exemples génériques souvent hors de propos (Ebola, Covid-19). | Structuration en syllogisme juridique : Base légale → Autorité compétente → Application au cas. |
L’apport du fine-tuning est particulièrement visible sur la structure logique des réponses. Le modèle a intériorisé un mode de raisonnement juridique : identification de la base légale, citation de l’autorité compétente (ANSES/EFSA), puis application au cas pratique. Les hallucinations, bien que drastiquement réduites, restent le dernier point d’attention — notamment sur les listes exhaustives où le modèle peut encore compléter par analogie sémantique des substances qu’il n’a pas mémorisées exactement.
Exemples de réponses : Modèle baseline vs fine-tuné
Les exemples ci-dessous comparent la génération du modèle de base (Qwen3-14B Q5_K_M) avec la version fine-tunée sur des questions de test.
Notes expérimentales :
- Afin d’obtenir des comparaisons pertinentes, les modèles utilisés correspondent au même modèle avant et après fine-tuning, avec les mêmes paramètres d’inférence.
- Certaines questions de cette partie peuvent obtenir une réponse pertinente avec des modèles cloud usuels (ChatGPT, Gemini, Mistral …), mais ne sera pas mentionné car hors-scope de ce projet (exploitation de modèles locaux pour utilisation agentique ultérieure).
Synthèse des performances
L’évaluation LLM-as-a-judge sur les 10 questions D001–D010 fait ressortir deux profils radicalement opposés.
Résultats baseline sur Qwen3
Quatre défaillances systématiques ont été observées sur l’ensemble du set de test :
- Domain shift vers la pharmacie humaine.
- Confrontée à “AMM” ou “PPP”, la baseline mobilise le Code de la santé publique et cite des autorités médicales (ANSM, HAS).
- Sur D001 (AMM d’urgence phytosanitaire), elle cite l’art. L.5121-7 CSP et illustre avec des exemples Ebola et COVID-19, sans aucun rapport avec la réglementation PPP régie par le CRPM et le Règlement 1107/2009.
- Hallucination sémantique sur les sigles.
- L’acronyme “LMR” devient “Ligne directrice de santé et sécurité au travail” (D005), “PPP” devient “Permiso de Plazas de Medicamentos” (D007).
- Le modèle invente une signification plausible dans un autre domaine plutôt que d’admettre son ignorance.
- Fabrication de références réglementaires.
- La baseline cite des règlements européens inexistants (ex. “Règlement (UE) 2018/603”) ou applique des textes hors-périmètre (Règlement (CE) n°89/391, droit du travail) pour répondre à des questions phytosanitaires.
- Génération verbeuse et vide.
- Les réponses de la baseline sont structurées, syntaxiquement correctes et confiantes (ce qui les rend d’autant plus trompeuses !).
- Sur D004 (avantages liste biocontrôle), elle produit sept points bien rédigés sans citer un seul article, en attribuant par erreur la gestion de la liste nationale à l’ADEME.
Apports du fine-tuning
Sur les mêmes questions, RegulAgro démontre une rupture qualitative nette :
-
Désambiguïsation immédiate du domaine. Le modèle ancre chaque réponse dans le corpus agrochimique dès les premières lignes : Code Rural (CRPM), Règlement 1107/2009, ANSES et EFSA comme autorités compétentes.
-
Précision juridique vérifiable. Les articles cités sont exacts et pertinents : art. L253-12 CRPM pour la durée de 12 mois d’une AMM d’urgence (D001), art. 18§1b du Règlement 396/2005 pour la LMR par défaut de 0,01 mg/kg (D005), art. 40 du Règlement 1107/2009 pour la procédure de reconnaissance mutuelle zonale (D007), art. L253-6 CRPM pour les avantages opérationnels de la liste biocontrôle (D004).
-
Raisonnement structuré. Le modèle adopte un syllogisme juridique systématique : base légale → autorité compétente → application au cas, y compris sur des questions à plusieurs sous-cas (D007 : distinction approbation européenne vs. nationale, avec procédures différentes pour chacun).
-
Absence d’hallucinations sur le périmètre entraîné. Aucune fabrication de règlement ou de sigle n’a été observée sur D001–D010. Le modèle sait distinguer les catégories réglementaires (PPP vs. biostimulant vs. biocontrôle) et ne les confond pas, même sur des questions frontières comme D003 (Trichoderma harzianum).
Ces résultats restent qualitatifs : l’évaluation LLM-as-a-judge par Gemini-3.5-Pro mesure la pertinence et la précision des citations, mais n’est pas encore complétée par une évaluation RAGAS sur un corpus étendu, prévue comme prochaine étape.
Portée et limites
Ce projet montre qu’un modèle open-weight 14B peut atteindre un niveau de précision réglementaire inaccessible à un généraliste, avec un pipeline entièrement reproductible sur infrastructure personnelle.
Les composants développés sont :
- Fine-tuning QLoRA sur du matériel grand public (2× RTX 5070 Ti) avec Unsloth
- Acquisition de données réglementaires complexes (EUR-Lex derrière WAF, ANSES open data)
- Pipeline de génération automatique de dataset Q&A via LLM local avec validation citations
- Évaluation rigoureuse : benchmark baseline avant tout entraînement, comparaison mesurable
- Déploiement local via Ollama (souveraineté des données, latence faible, pas d’API tierce)
Bien que le modèle fine-tuné soit largement supérieure et utilisable, plusieurs axes d’amélioration sont prévus pour atteindre un standard de production :
- Augmentation du dataset d’évaluation : Génération d’un nombre supérieur de questions pour tester la robustesse et la généralisation du modèle au-delà des 10 questions initiales.
- Réduction des Hallucinations Énumératives : Comportement typique d’un modèle qui a compris la structure attendue (une liste à puces) mais qui comble les lacunes de sa mémoire par des probabilités sémantiques. Ajouter des exemples dans le dataset où le modèle répond de manière concise.
- Amélioration du Recall : Le modèle a acquis le ton, mais pas encore toute la connaissance. Augmenter le rang LoRA (passer de 64 à 128) ou augmenter le ratio d’époques sur les documents réglementaires bruts par rapport aux paires Q&A générées.
Le fine-tuning n’est pas sans limites. Les connaissances sont figées à la date du dataset : une nouvelle substance approuvée ou un règlement d’exécution publié après la dernière mise à jour du corpus ne sera pas connu du modèle. En production, la cible est le combo RAG + fine-tuning : le modèle fine-tuné maîtrise le raisonnement juridique et la structure de citation ; le RAG lui fournit les mises à jour sans nécessiter de ré-entraînement.
Pour avoir plus d’informations sur l’objectif global de ce projet (i.e. le développement d’agents autonomes), consultez le projet Nexus.