Nexus
Écosystème de veille automatisée et assistée par IA, pensé pour la recherche scientifique. Orchestration d'agents IA, RAG avancé et LLMs locaux dans une interface utilisateur permettant à l'utilisateur de converser avec sa veille et ses données.
En 2023, PubMed indexait plus de 1,5 million nouvelles publications (NSF, 2023). Un chercheur à temps plein ne peut en lire que quelques centaines par an, le reste disparaîssant dans le bruit. À titre personnel, mon activité d’indépendant dépend de ma capacité à rester à jour, mais paradoxalement impacte directement mon temps disponible à ma veille.
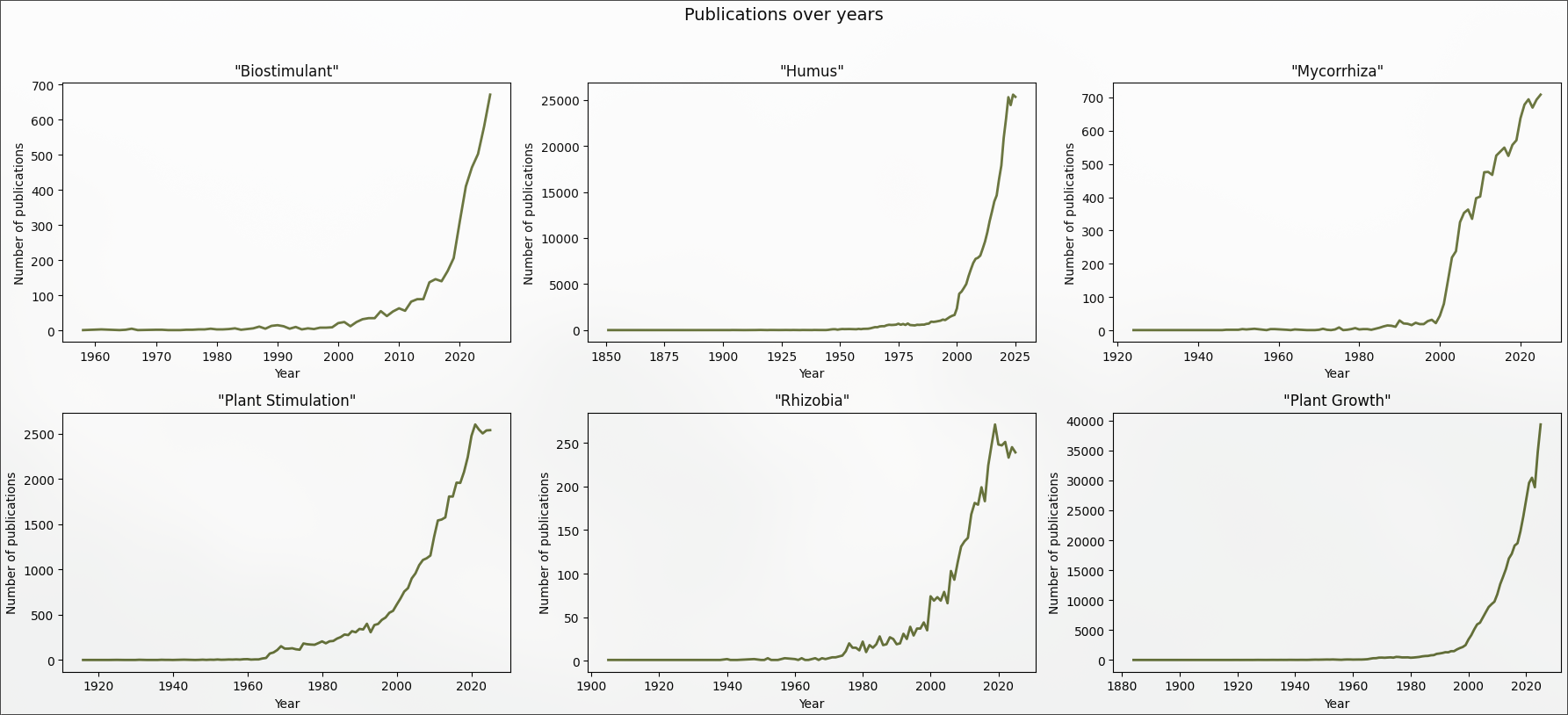
La plupart des chercheurs font face au même paradoxe : plus le domaine avance vite, moins ils ont le temps de le suivre. Les outils existants (Zotero, Google Scholar Alerts, Lens.org) couvrent chaque besoin séparément, mais aucun ne propose une expérience intégrée et personnelle.
Mon précédent projet Alexandria est né de ce constat. L’idée était de construire un écosystème complet centré autour de la veille bibliographique, puis d’exploiter les avancées récentes en IA générative locale (i.e. un chatbot comme Mistral, Gemini, … qui fonctionne sur une machine personnelle) pour permettre à un chercheur de converser avec sa base bibliographique.
Au vu des résultats obtenus avec ce projet, j’ai étendu son scope à d’autres éléments pertinents dans un milieu scientifique : articles bibliographiques complets, documentations internes, et capacité de réflexion étendue du modèle de langage utilisé. Chaque source d’information est indexée, enrichie sémantiquement, et rendue interrogeable via une interface de conversation naturelle.
L’ensemble repose, dans mon exemple, sur des LLMs locaux garantissant la confidentialité des données, un point non négociable pour la recherche industrielle sensible.
Les principaux défis techniques :
- Orchestration de plusieurs agents IA spécialisés sans explosion de latence,
- Gestion de la qualité des extractions d’entités sur des textes scientifiques à vocabulaire dense,
- Conception d’une interface suffisamment généraliste pour couvrir des cas d’usage très différents d’un utilisateur ou d’une structure à une autre.
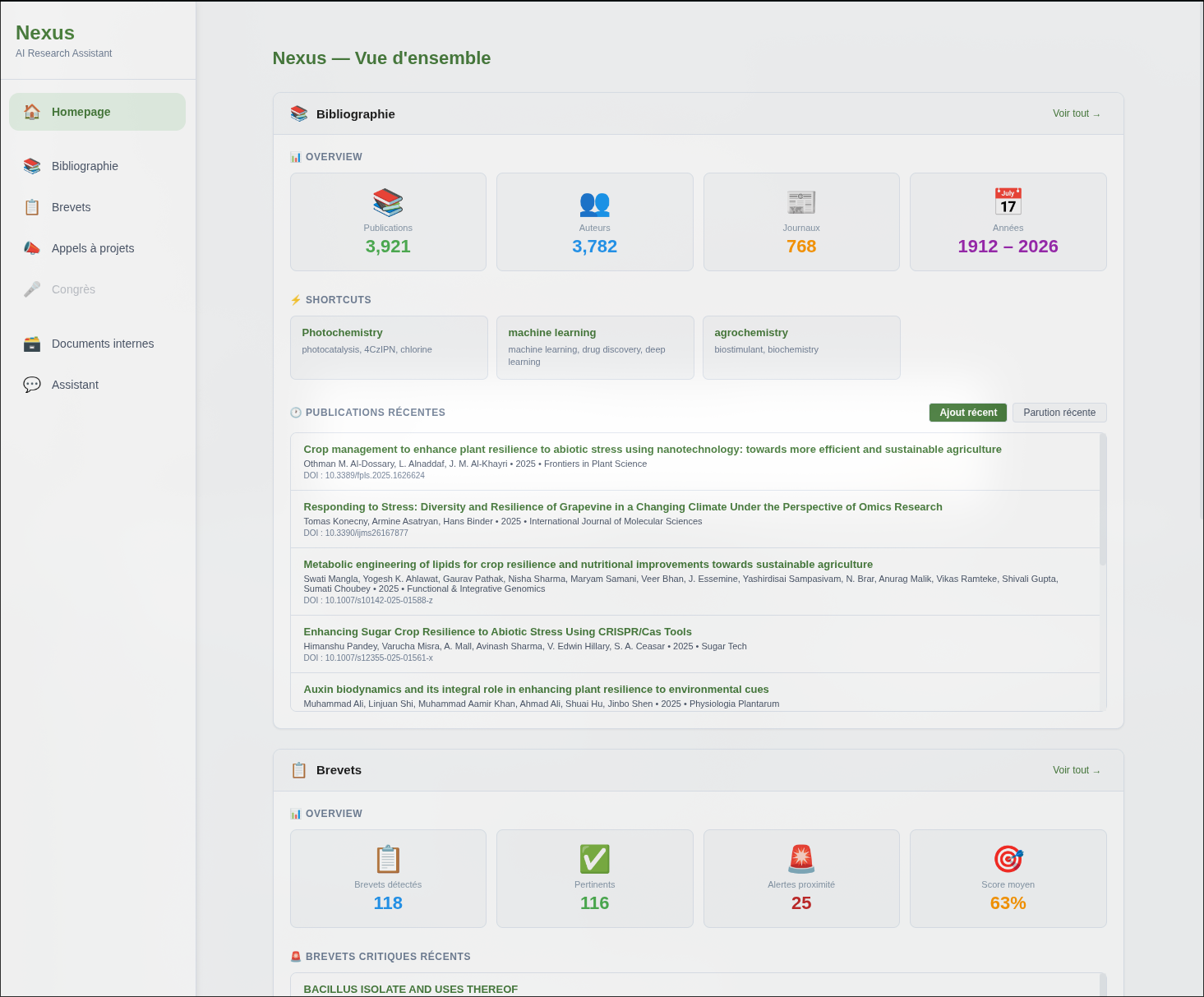
Veille personnelle automatisée
Le module de veille bibliographique est le cœur de Nexus.
Il permet d’importer des publications depuis Semantic Scholar, arXiv et Crossref, par dépôt direct de PDF, ou par importation depuis un autre gestionnaire de bibliographie (Zotero, Mendeley).
Ces publications sont ensuite stockées dans une base locale enrichie automatiquement : résumé, mots-clés, classification thématique, embeddings sémantiques.
La bibliothèque est ensuite explorable selon plusieurs axes : recherche textuelle, filtres par auteur, journal, année, ou par domaine. Une fonctionnalité de recherche par similarité sémantique a aussi été implémentée : à partir d’un article donné, le système identifie les papiers les plus proches présents dans la base de données, indépendamment des mots-clés.
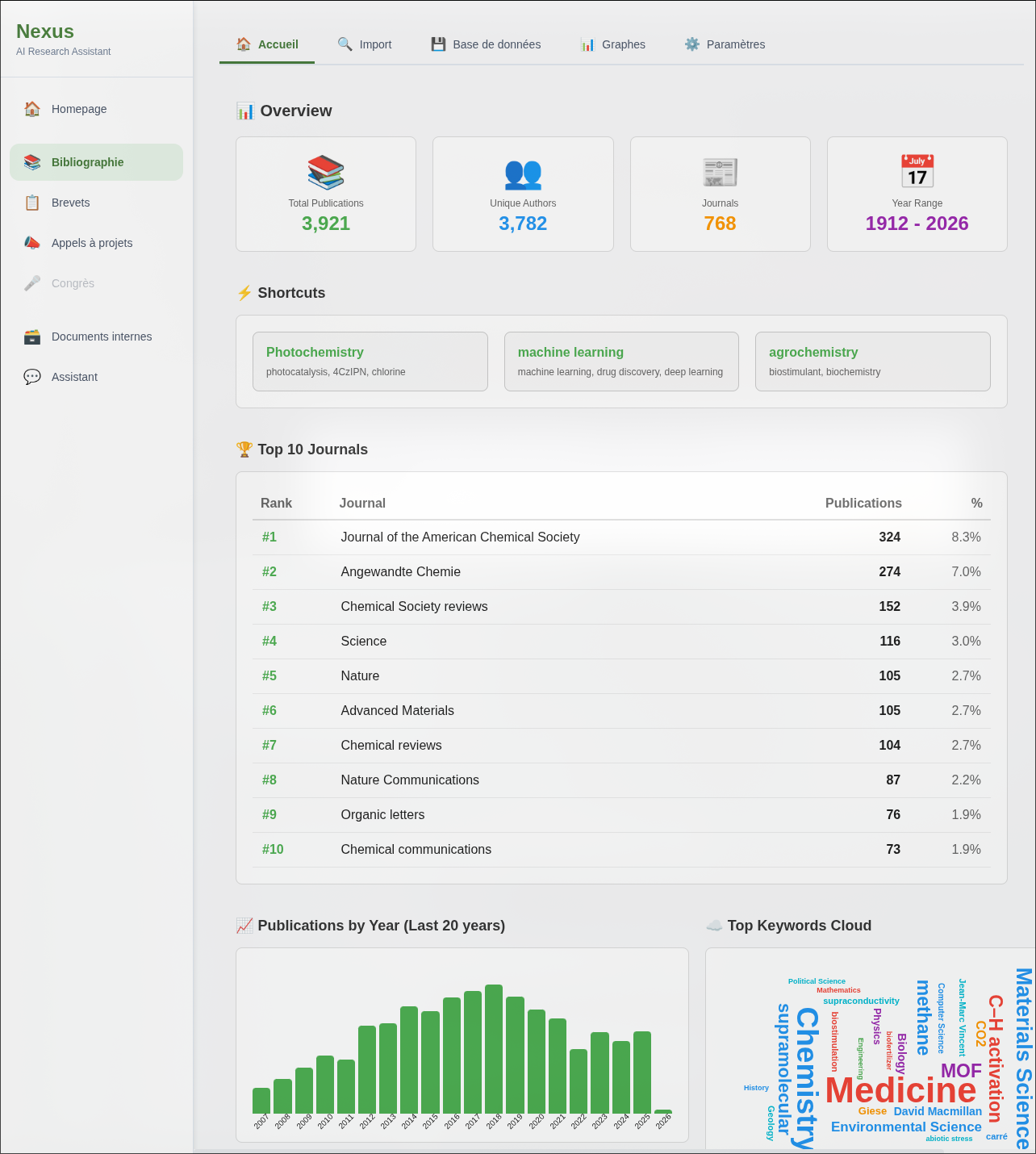
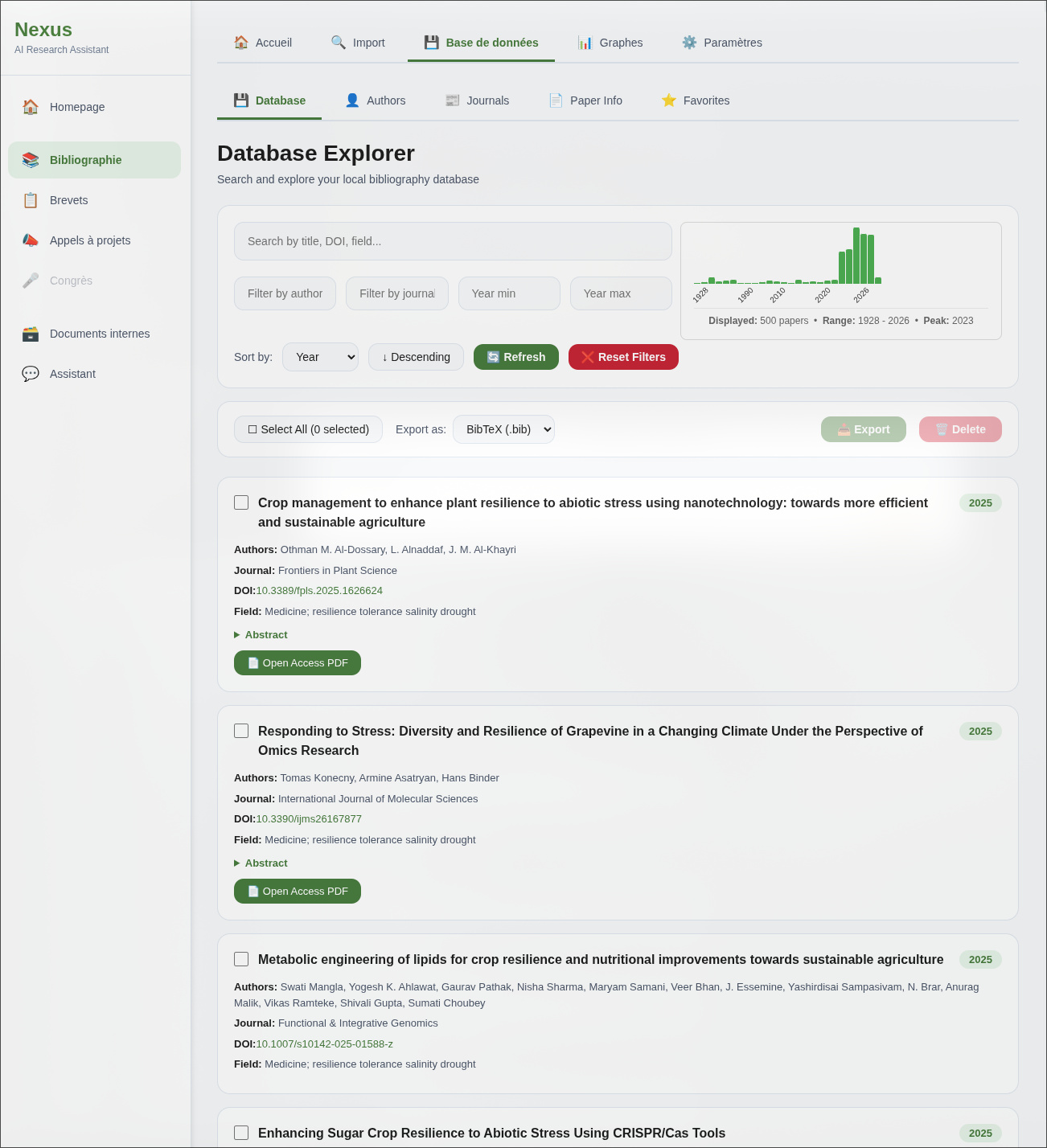
Les imports sont rapides : un lot de 200 articles depuis Semantic Scholar ou arXiv est récupéré en quelques dizaines de secondes puis stockés dans la base de donnée locale. À titre d’exemple, la base utilisée dans les démonstrations précédentes regroupe 4000 articles et a été constituée en une demi-heure.
Stocker la bibliothèque localement n’est pas un détail, mais signifie plusieurs choses primordiales dans ce projet :
- aucune donnée ne transite par un serveur externe,
- les recherches ne sont pas loguées,
- l’accès reste possible hors ligne,
- les données sont facilement partageables et archivables.
Pour les équipes travaillant sur des sujets sensibles ou soumises à des contraintes de confidentialité (NDA, propriété intellectuelle), c’est un avantage décisif par rapport aux solutions cloud.
Cette base de donnée structurée permet par ailleurs une exploitation avancée dans une logique de prise de décision : un agent IA peut, par exemple, interroger la base pour identifier les articles les plus pertinents sur un sujet donné, extraire les méthodes utilisées, ou faire du clustering thématique pour faire émerger des tendances dans la littérature. Ces points seront détaillés dans la suite de cet article.
D’autres types de veille sont bien entendu incorporables, conjointement ou en remplacement à la veille bibliographique.
Documentation interne
Un LLM, aussi puissant soit-il, ne peut traiter qu’une quantité limitée de texte à la fois en raison de sa fenêtre de contexte. Même les modèles les plus récents plafonnent à quelques centaines de pages ! Pour un chercheur dont la bibliothèque compte des milliers d’articles, cette contrainte est rédhibitoire si l’on cherche à “parler” à sa documentation.
L’approche exploitée au sein de Nexus correspond aux graphes de connaissances. Au lieu de donner un document formatté à un modèle de langage, on lui donne accès à une représentation graphique de connaissances, permettant un accès au savoir bien plus optimisé.
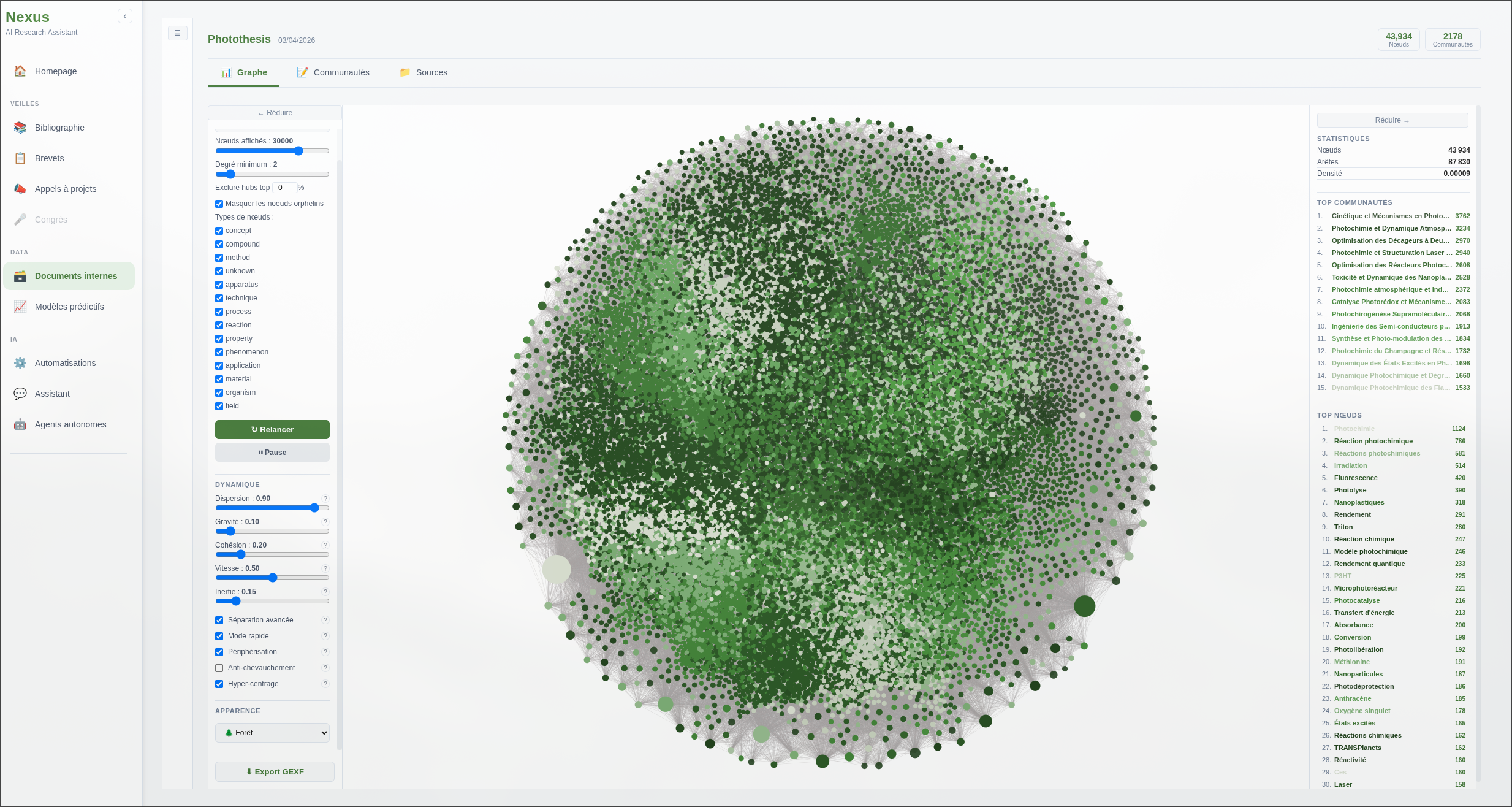
Ces graphes générés par le système, via un pipeline d’extraction, permettent d’en tirer des entités (molécules, gènes, organismes, techniques, auteurs, institutions…) et les relations qui les lient (inhibe, catalyse, produit, co-auteur de…).
Les cas d’usages ne sont pas que pour de la bibliographie. Ces types de graphes de connaissances permettent de résumer et d’organiser un nombre très important de documents : des dossiers entiers de notes de réunions, un ensemble de rapports et de thèses … Pour plus d’informations concernant les techniques de GraphRAG (développement et cas d’usage), consultez le projet BioGraphRAG.
Le graphe présenté dans cette partie a été généré avec un corpus de 25 publications, et permet des requêtes impossibles avec une simple recherche vectorielle : “quelles molécules ont été testées contre cette cible par ce groupe de recherche ?” ou “quelles techniques sont associées à ce concept dans ma bibliothèque ?”.
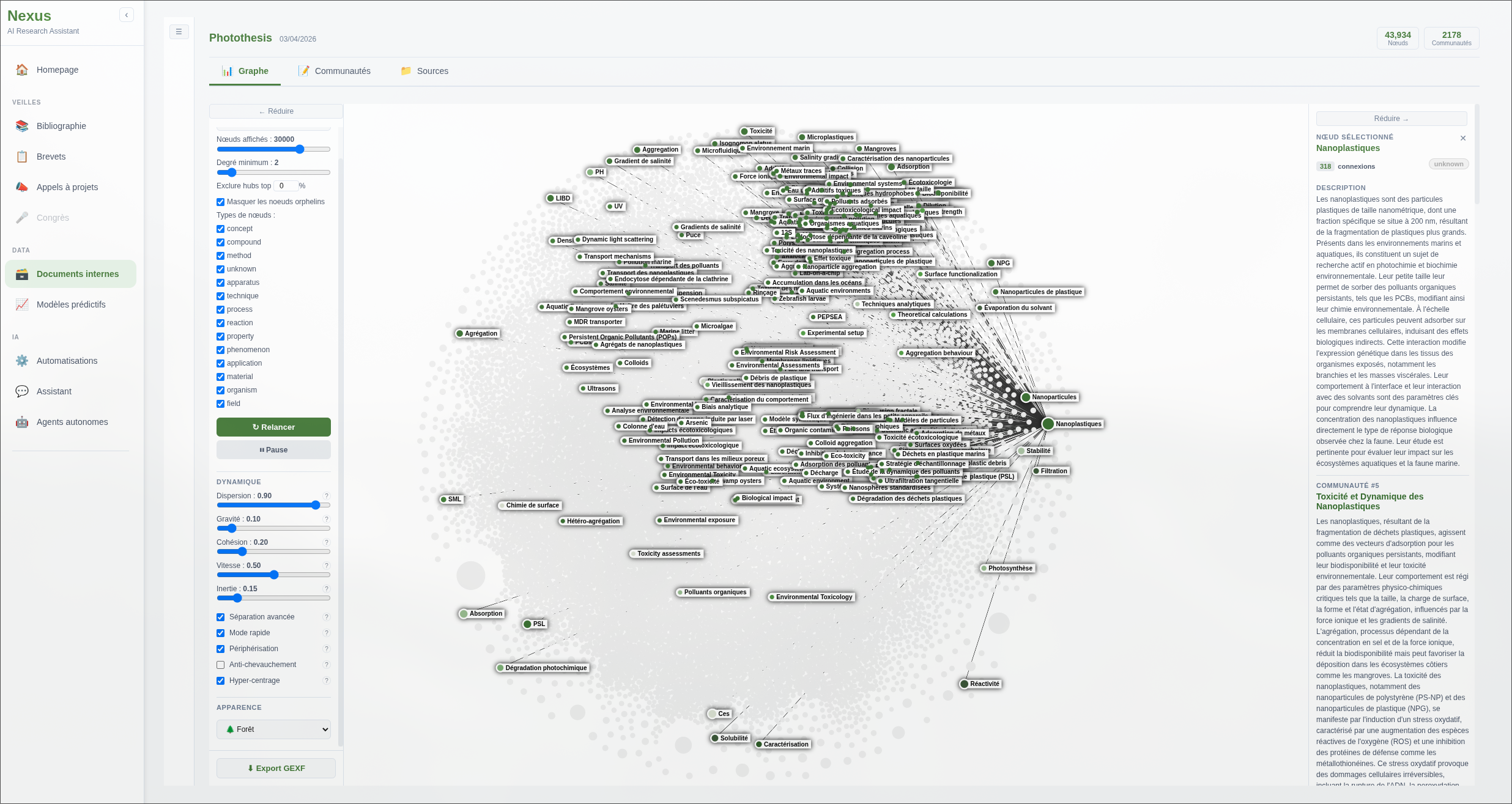
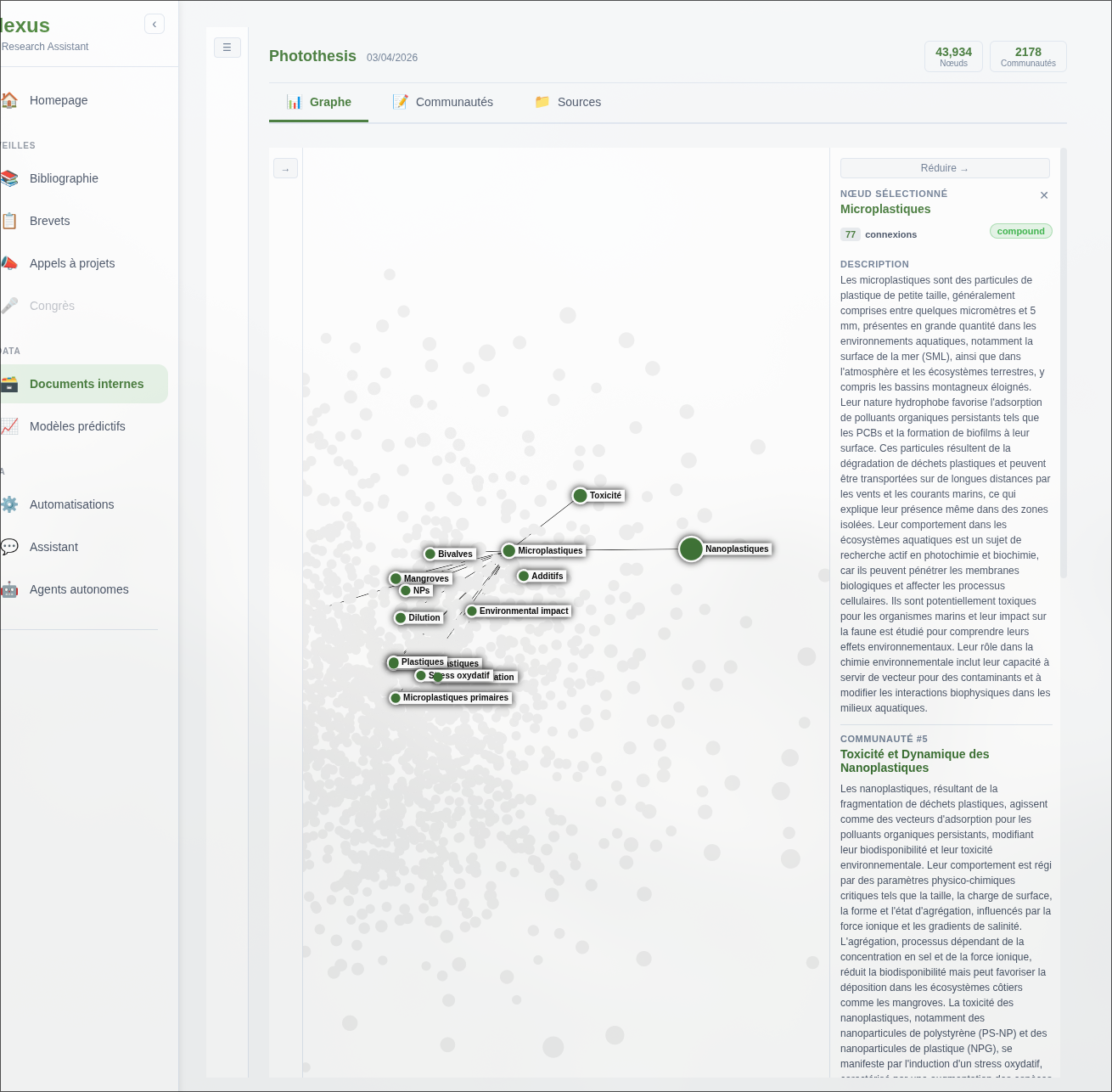
Le graphe est visualisable et interrogeable directement depuis l’interface, ou utilisé en arrière-plan par l’agent de recherche pour enrichir ses réponses.
Pour plus d’informations sur cette partie, consultez le focus sur la génération et l’exploitation de GraphRAG
Architecture d’IA agentique
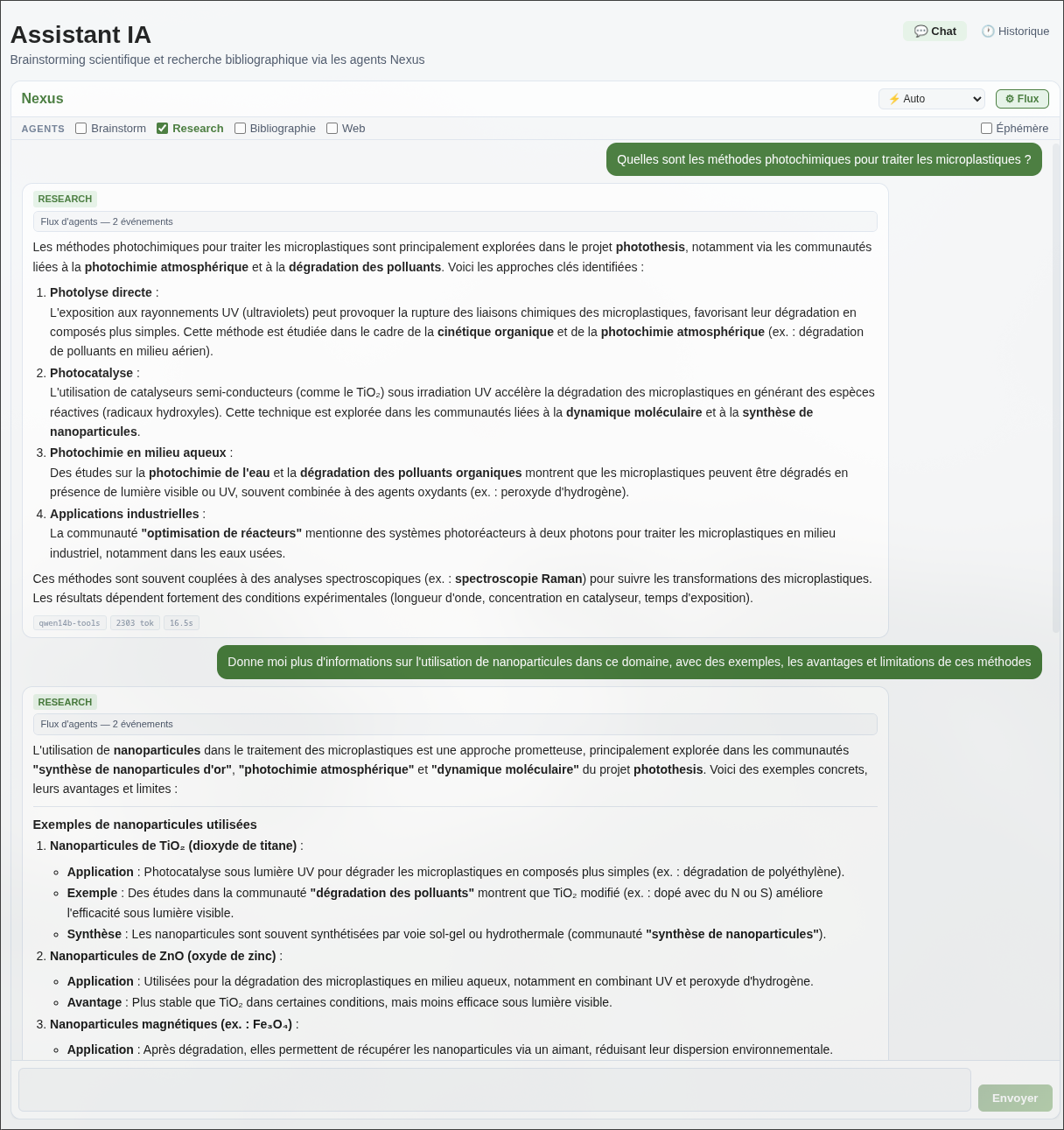
Le ResearchAgent est un agent IA disposant d’un accès structuré à l’ensemble des sources de Nexus : base de veille(s), graphe de connaissances, documents internes.
Selon la question posée, il sélectionne automatiquement les outils pertinents, récupère les informations nécessaires, et synthétise une réponse argumentée avec sources citées.
L’architecture repose sur LangGraph, qui permet de définir des graphes d’exécution conditionnels. L’agent peut par exemple faire une première recherche, évaluer si le résultat est suffisant, et décider de creuser une piste complémentaire avant de répondre.
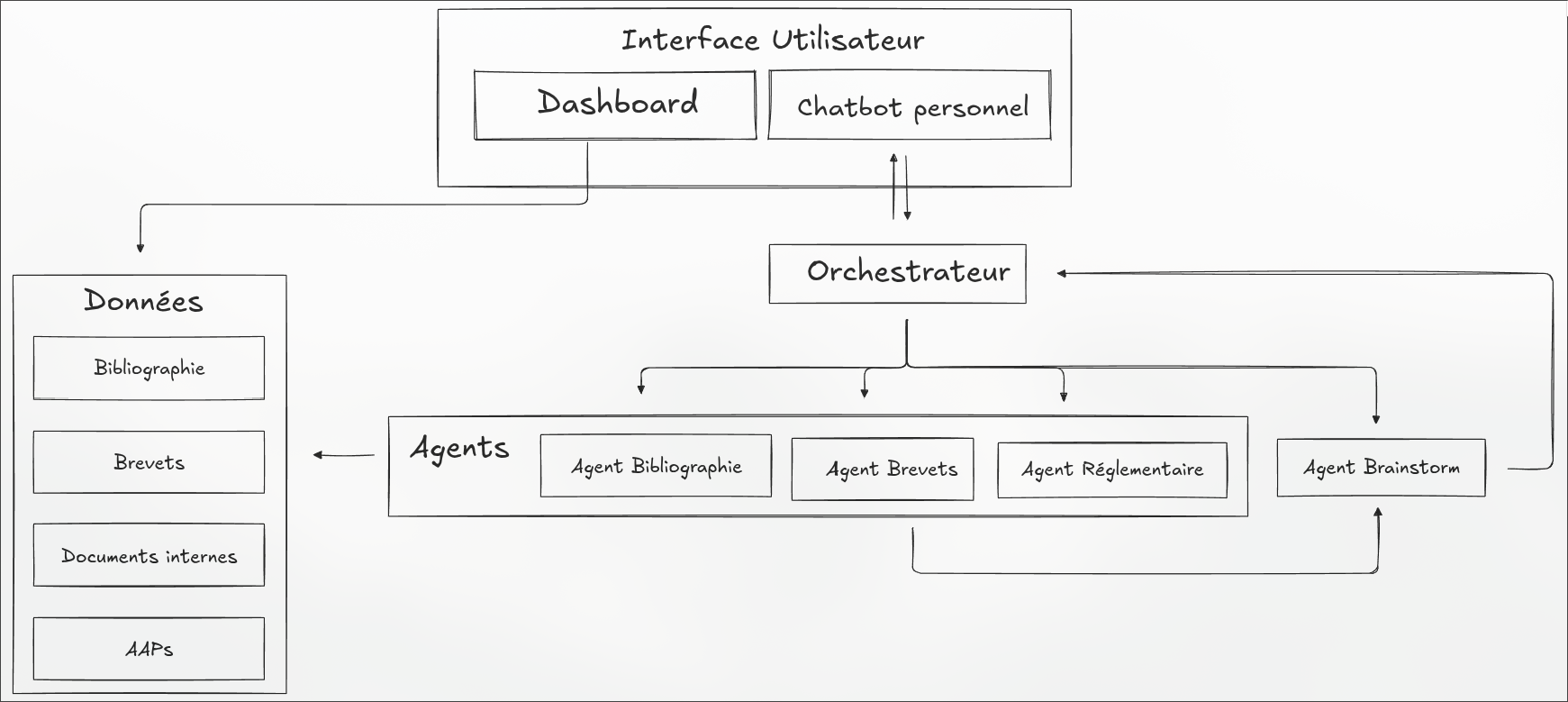
LangGraph permet d’orchestrer plusieurs agents spécialisés avec une logique conditionnelle fine : boucles de réflexion, appels parallèles, reprise en cas d’échec.
Chaque agent dispose d’un ensemble d’outils (qui correspondent grossièrement à des fonctions programmatiques) qu’il peut invoquer selon le besoin : recherche vectorielle, requête sur le graphe, recherche web, résumé de document.
Le choix du LLM local est délibéré. Les API cloud (GPT-5, Claude, Gemini) sont plus performantes mais posent deux problèmes dans ce contexte :
- le coût variable selon l’usage,
- l’envoi de données potentiellement sensibles vers des serveurs tiers.
Faire tourner le modèle en local résout les deux, au prix d’un investissement matériel, mais avec une souveraineté totale sur les données.
Assistant de Recherche
L’interface de chat est le point d’entrée unifié vers l’ensemble de l’écosystème Nexus.
En langage naturel, le chercheur peut interroger sa bibliothèque bibliographique :
- Quels articles récents traitent de la photocatalyse au ruthénium ?
- Génère moi une veille bibliographique complète des articles récents traitant des dernières avancées en biostimulation focalisée sur la rhizosphère
- Y a-t-il des articles dans ma base qui relient la microbiologie du sol à la nutrition azotée ?
- Quels journaux publient le plus sur les matériaux photovoltaïques, et quel est leur facteur d’impact ?
Bien entendu, si d’autres types de veille sont inclus dans Nexus, les questions peuvent directement les cibler. Et, mieux encore, les requêtes utilisateurs peuvent croiser plusieurs bases de connaissances simultanément. Ainsi le système permet par exemple d’explorer un espace concurrentiel en recoupant différentes veilles, ou de générer des réponses en liant une veille à des documents internes.
Enfin, Nexus permet de brainstormer avec un agent. Celui-ci est conçu pour explorer des hypothèses, identifier des connexions inattendues entre domaines, et suggérer des pistes de recherche à partir du corpus disponible.
Chaque réponse est sourcée : l’agent cite les articles, brevets ou documents internes dont il s’est servi, permettant à l’utilisateur de vérifier et d’approfondir.
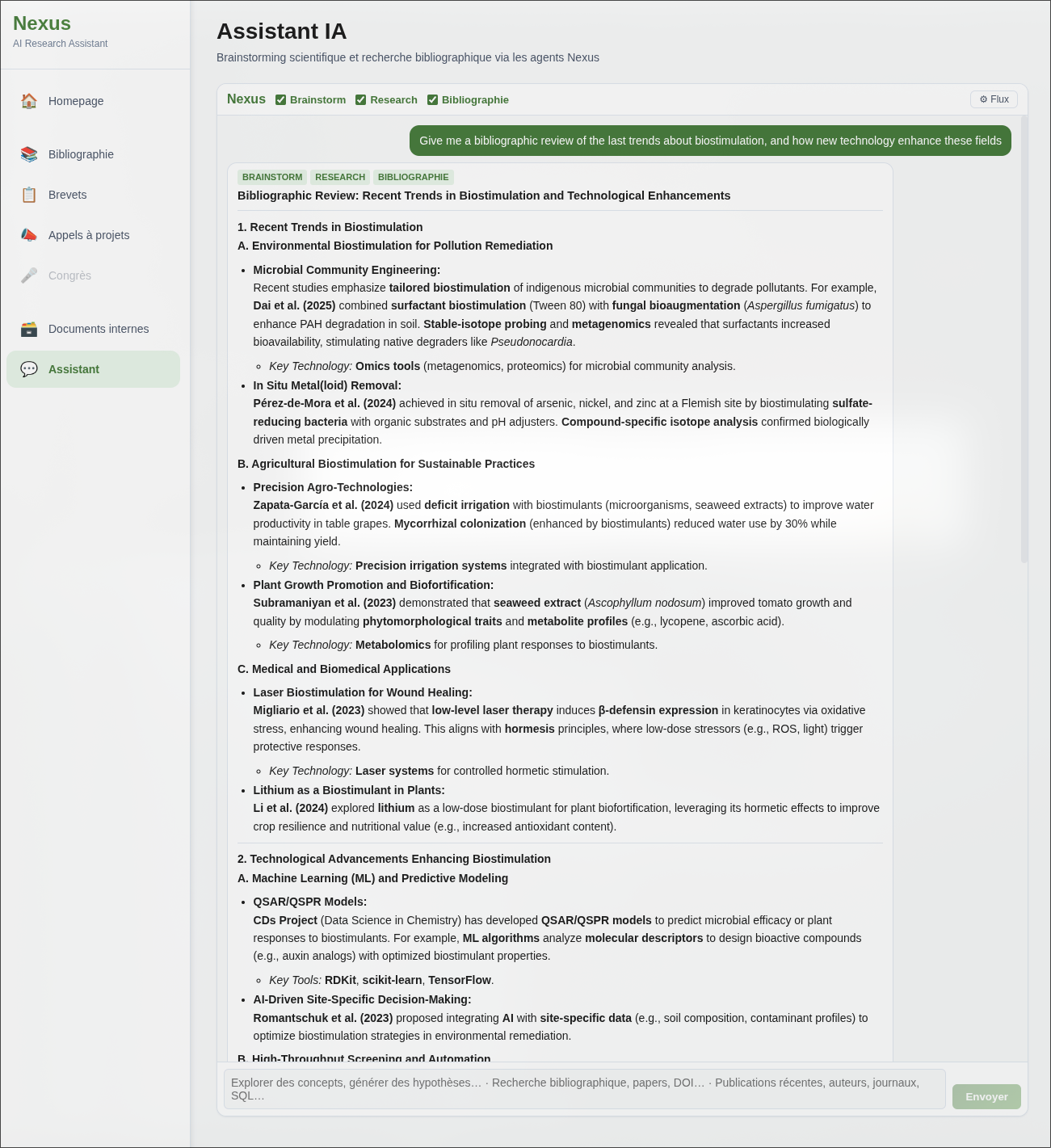
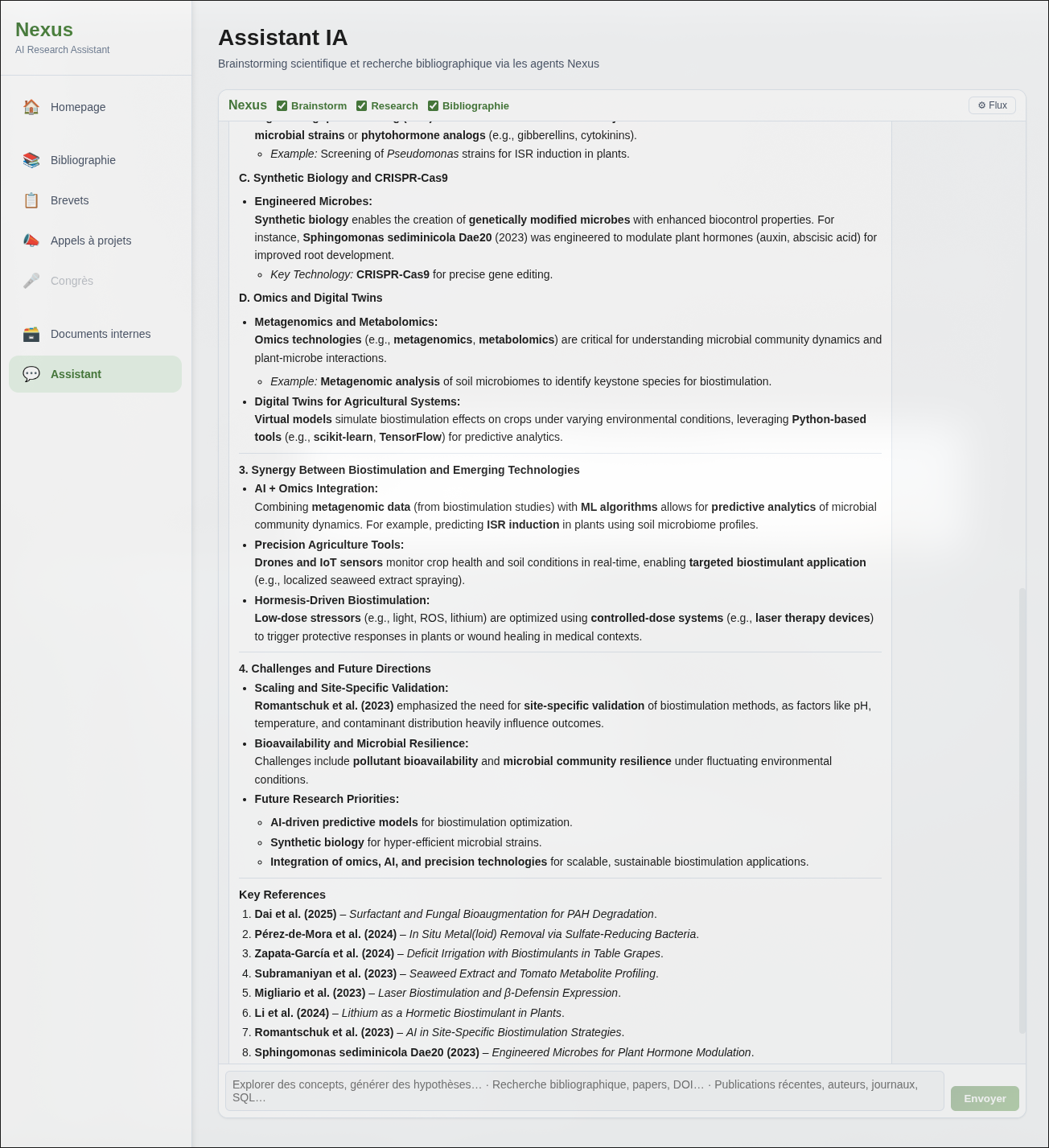
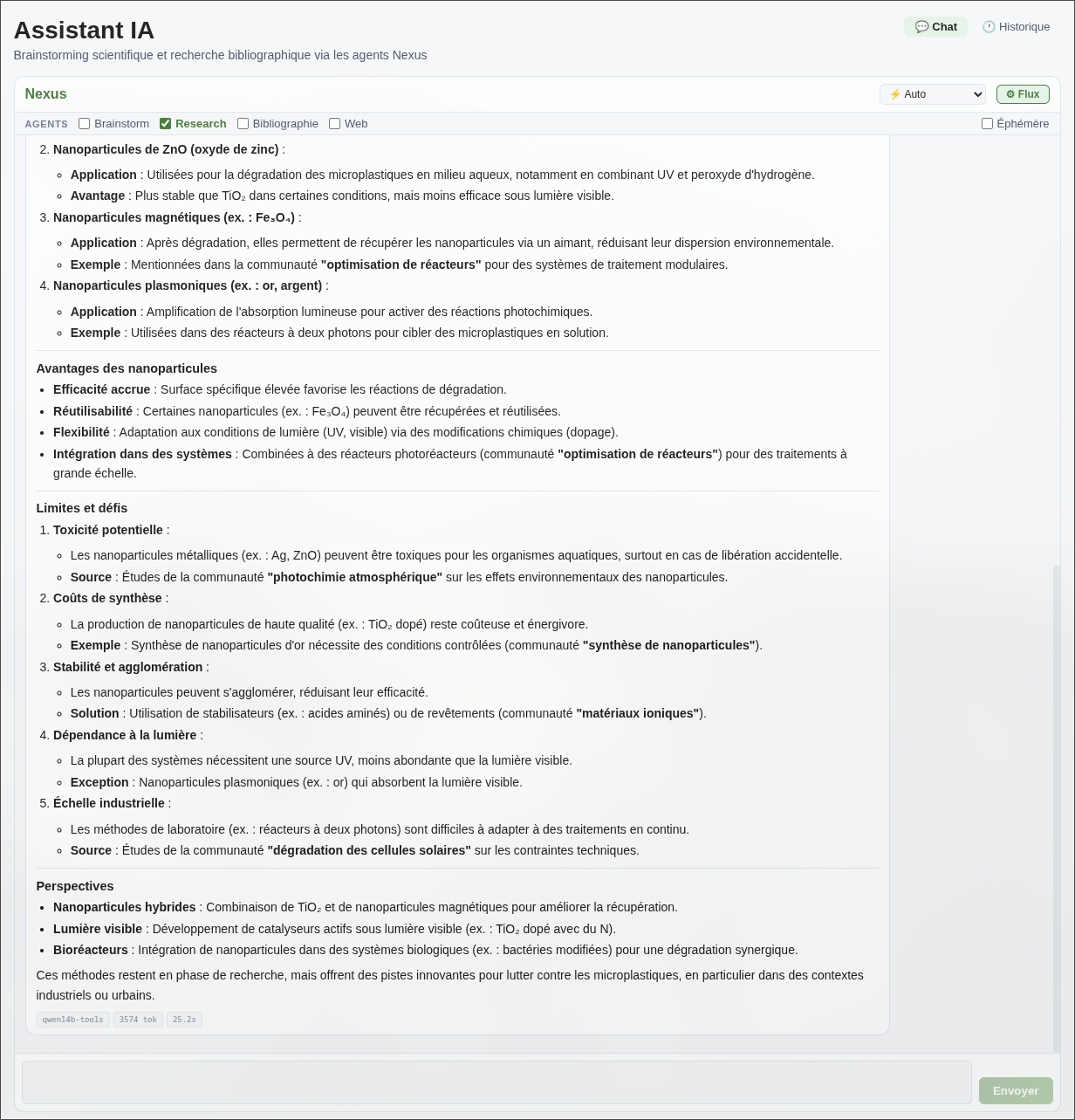
Sur cet exemple, la revue bibliographique a été générée en 3 minutes. Produite manuellement, la même synthèse aurait demandé plusieurs heures de lecture sélective. Ce système ne remplace pas la lecture ou la conception de veilles, mais permet de cibler les articles qui méritent l’attention du lecteur.
Nexus démontre qu’il est possible de construire un assistant de recherche scientifique performant, privé, et souverain, sans dépendance de services cloud propriétaires. L’intégration de sources hétérogènes (articles, brevets, documents internes) dans un écosystème cohérent, interrogeable en langage naturel, représente un gain de temps significatif pour les équipes de R&D.
Les limites actuelles reposent sur la qualité des extractions du graphe de connaissances, fortement dépendantes du LLM local utilisé, et sur la configuration d’un tel système, demandant une expertise technique et une connaissance du domaine scientifique.
Les évolutions en cours d’études incluent la prise en charge d’autres types de veilles automatisées, avec incorporation de systèmes de recommandation évolutifs liés à un système d’alerte externe.