Data Visualization
Types de visualisation
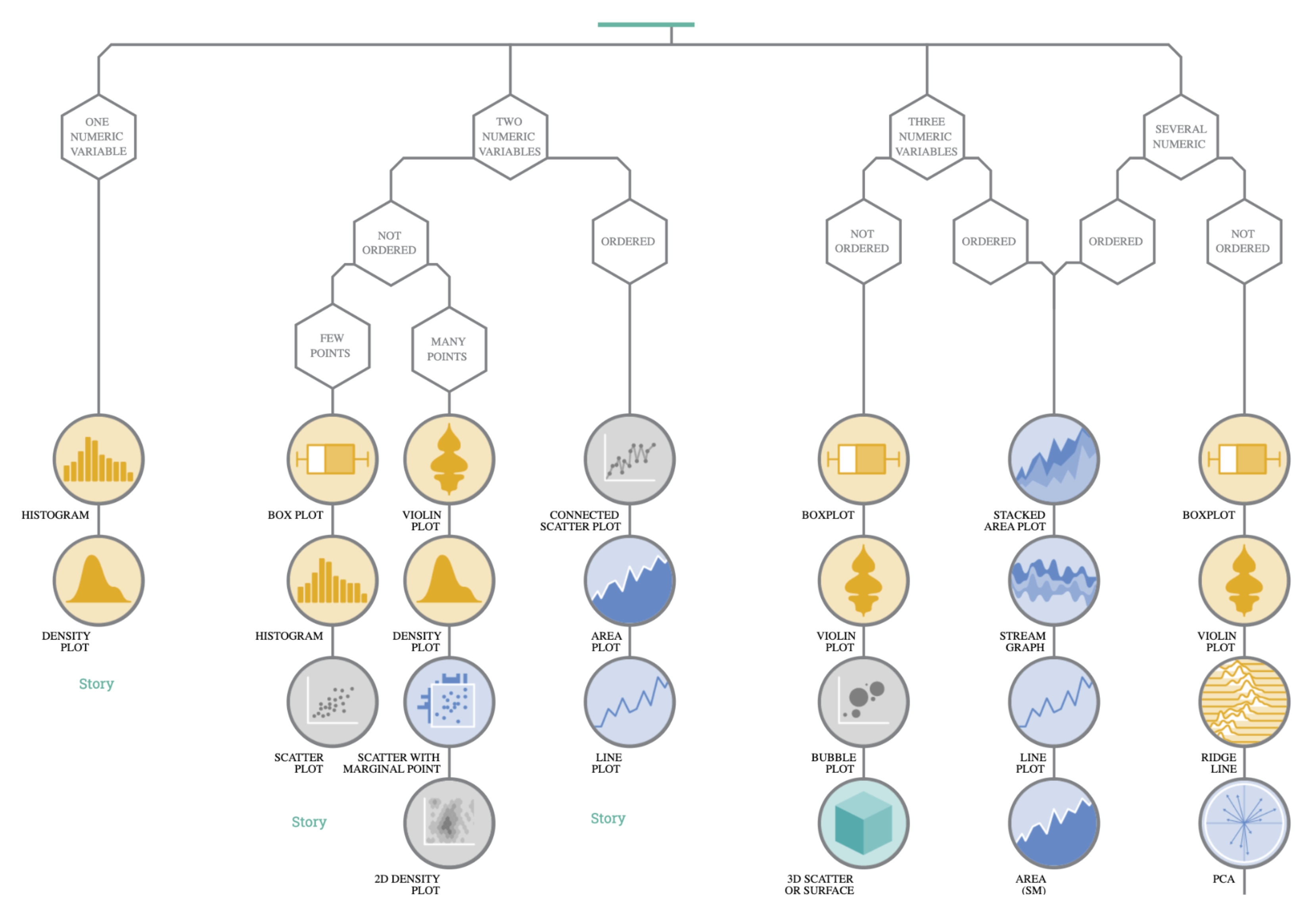
[From data to Viz | Find the graphic you need]
Globalement, on utilise :
Pandaspour la simplicité, l’analyse exploratoire primaireMatplotlibpour des graphs complets et entièrement personnalisables (examples)Seabornpour de l’exploration statistique (examples)plotlypour des graphs interactifs.
Lineplot
Visualisation en fonction du temps
[!bug]- Code
import matplotlib.pyplot as plt import numpy as np # Données temporelles simples temps = np.arange(0, 10, 0.1) valeurs = np.sin(temps) plt.figure(figsize=(10, 6)) plt.plot(temps, valeurs) plt.xlabel('Temps') plt.ylabel('Valeur') plt.title('Evolution temporelle') plt.grid(True, alpha=0.3) plt.show()
Barplot
Variations:
- stacked barplot and 100% stacked barplot: great to show split over categories
- horizontal barplot (e.g. when labels are very long)
[!bug]- Code
import matplotlib.pyplot as plt categories = ['A', 'B', 'C', 'D'] valeurs = [23, 45, 56, 33] plt.figure(figsize=(8, 6)) plt.bar(categories, valeurs) plt.xlabel('Catégories') plt.ylabel('Valeurs') plt.title('Comparaison par catégories') plt.show()
[!bug]- Code
# Stacked barplot import numpy as np categories = ['A', 'B', 'C', 'D'] valeurs1 = [23, 45, 56, 33] valeurs2 = [17, 28, 35, 42] plt.figure(figsize=(8, 6)) plt.bar(categories, valeurs1, label='Groupe 1') plt.bar(categories, valeurs2, bottom=valeurs1, label='Groupe 2') plt.xlabel('Catégories') plt.ylabel('Valeurs') plt.title('Barplot empilé') plt.legend() plt.show() # Horizontal barplot plt.figure(figsize=(8, 6)) plt.barh(categories, valeurs) plt.xlabel('Valeurs') plt.ylabel('Catégories') plt.title('Barplot horizontal') plt.show()
Histogram or density plot
Visualisation de la distribution.
[!bug]- Code
import matplotlib.pyplot as plt import numpy as np # Génération de données donnees = np.random.normal(100, 15, 1000) # Histogram plt.figure(figsize=(10, 6)) plt.hist(donnees, bins=30, edgecolor='black', alpha=0.7) plt.xlabel('Valeur') plt.ylabel('Fréquence') plt.title('Distribution - Histogramme') plt.show() # Density plot import seaborn as sns plt.figure(figsize=(10, 6)) sns.kdeplot(donnees, fill=True) plt.xlabel('Valeur') plt.ylabel('Densité') plt.title('Distribution - Density plot') plt.show()
Boxplot or violinplot
Comparer les distributions. Les boxplots sont utiles pour trouver les outliers.
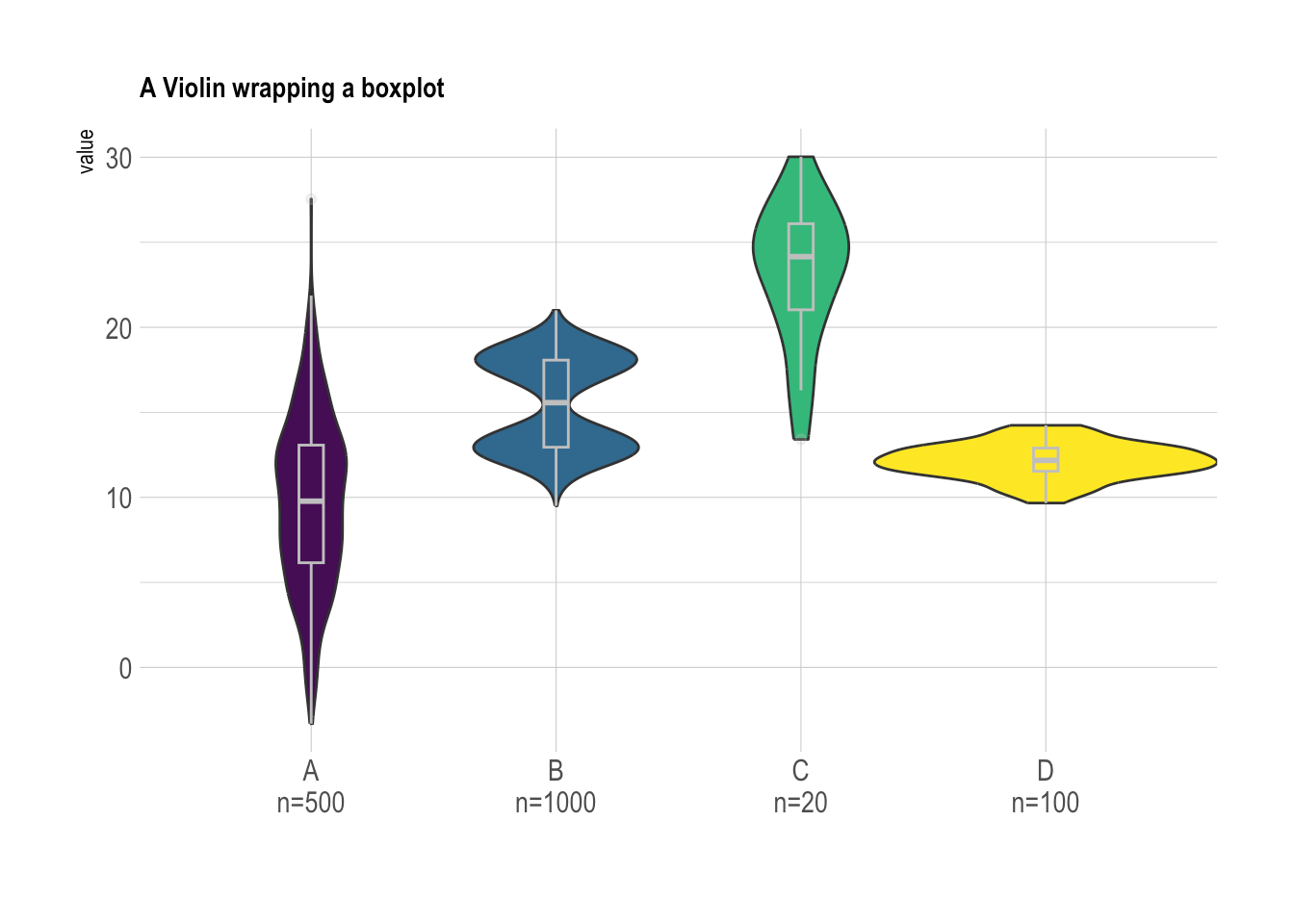
[!bug]- Code
import matplotlib.pyplot as plt import seaborn as sns import numpy as np # Données pour plusieurs groupes groupe_a = np.random.normal(100, 10, 100) groupe_b = np.random.normal(110, 15, 100) groupe_c = np.random.normal(95, 12, 100) donnees = [groupe_a, groupe_b, groupe_c] # Boxplot plt.figure(figsize=(10, 6)) plt.boxplot(donnees, labels=['Groupe A', 'Groupe B', 'Groupe C']) plt.ylabel('Valeurs') plt.title('Comparaison des distributions - Boxplot') plt.show() # Violinplot avec seaborn import pandas as pd df = pd.DataFrame({ 'valeur': np.concatenate([groupe_a, groupe_b, groupe_c]), 'groupe': ['A']*100 + ['B']*100 + ['C']*100 }) plt.figure(figsize=(10, 6)) sns.violinplot(data=df, x='groupe', y='valeur') plt.title('Comparaison des distributions - Violinplot') plt.show() # Autres graphs avec seaborn fig, axs = plt.subplots(2, 2, figsize=(10, 4)) sns.boxplot(data=df, x='groupe', y='valeur', hue='hue', ax=axs[0, 0]); sns.boxenplot(data=df, x='groupe', y='valeur', hue='hue', ax=axs[0, 1]); sns.stripplot(data=df, x='groupe', y='valeur', hue='hue', ax=axs[1, 0]); sns.violinplot(data=df, x='groupe', y='valeur', hue='hue', ax=axs[1, 1]);

Scatterplot
Relations entre variables numériques

[!bug]- Code
import matplotlib.pyplot as plt import numpy as np # Deux variables corrélées x = np.random.normal(50, 10, 100) y = 2 * x + np.random.normal(0, 5, 100) plt.figure(figsize=(10, 6)) plt.scatter(x, y, alpha=0.6) plt.xlabel('Variable X') plt.ylabel('Variable Y') plt.title('Relation entre deux variables') plt.show()
Matplotlib
Maintenant que tu maîtrises les bases, on peut se demander si une visualisation brute suffit vraiment à captiver ton audience ? La personnalisation fait toute la différence entre un graphique fonctionnel et une dataviz mémorable !
Style et thèmes globaux
[!bug]- Code
import matplotlib.pyplot as plt import seaborn as sns # Utiliser un style prédéfini plt.style.use('seaborn-v0_8-darkgrid') # Options: 'ggplot', 'bmh', 'fivethirtyeight' # Ou configurer un thème seaborn sns.set_theme(style="whitegrid", palette="pastel") # Revenir au style par défaut plt.style.use('default')Styles disponibles :
print(plt.style.available)
Couleurs et palettes
[!bug]- Code
import matplotlib.pyplot as plt import seaborn as sns import numpy as np x = np.arange(5) y = [3, 7, 2, 5, 8] # Couleurs personnalisées couleurs = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#FFA07A', '#98D8C8'] plt.figure(figsize=(10, 6)) plt.bar(x, y, color=couleurs, edgecolor='black', linewidth=1.5) plt.title('Palette personnalisée') plt.show() # Utiliser une colormap valeurs = np.random.rand(50) plt.figure(figsize=(10, 6)) plt.scatter(range(50), valeurs, c=valeurs, cmap='viridis', s=100) plt.colorbar(label='Intensité') plt.title('Colormap viridis') plt.show() # Palettes Seaborn sns.set_palette("husl") # Options: "deep", "muted", "bright", "pastel", "dark", "colorblind"Créer sa propre palette :
ma_palette = sns.color_palette(["#9b59b6", "#3498db", "#95a5a6", "#e74c3c", "#34495e"]) sns.set_palette(ma_palette)
Polices et textes
[!bug]- Code
import matplotlib.pyplot as plt plt.figure(figsize=(10, 6)) # Configuration globale des polices plt.rcParams.update({ 'font.size': 12, 'font.family': 'sans-serif', 'font.sans-serif': ['Arial'], 'axes.titlesize': 16, 'axes.titleweight': 'bold', 'axes.labelsize': 14, 'xtick.labelsize': 11, 'ytick.labelsize': 11, 'legend.fontsize': 11 }) plt.plot([1, 2, 3, 4], [1, 4, 2, 3]) plt.title('Titre avec police personnalisée', fontsize=18, fontweight='bold', color='#2C3E50') plt.xlabel('Axe X', fontsize=14, style='italic') plt.ylabel('Axe Y', fontsize=14) # Ajouter du texte sur le graphique plt.text(2.5, 3, 'Annotation importante', fontsize=12, bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5)) plt.show()
Grilles et axes
[!bug]- Code
import matplotlib.pyplot as plt import numpy as np x = np.linspace(0, 10, 100) y = np.sin(x) fig, axes = plt.subplots(2, 2, figsize=(12, 10)) # Sans grille axes[0, 0].plot(x, y) axes[0, 0].set_title('Sans grille') # Grille basique axes[0, 1].plot(x, y) axes[0, 1].grid(True) axes[0, 1].set_title('Grille basique') # Grille personnalisée axes[1, 0].plot(x, y) axes[1, 0].grid(True, linestyle='--', linewidth=0.5, alpha=0.7, color='gray') axes[1, 0].set_title('Grille personnalisée') # Grille mineure axes[1, 1].plot(x, y) axes[1, 1].grid(True, which='major', linestyle='-', linewidth=0.8, alpha=0.7) axes[1, 1].grid(True, which='minor', linestyle=':', linewidth=0.5, alpha=0.4) axes[1, 1].minorticks_on() axes[1, 1].set_title('Grille majeure et mineure') plt.tight_layout() plt.show()
[!bug]- Personnalisation des axes
fig, ax = plt.subplots(figsize=(10, 6)) ax.plot([1, 2, 3, 4], [1, 4, 2, 3]) # Limites des axes ax.set_xlim(0, 5) ax.set_ylim(0, 5) # Échelle logarithmique # ax.set_yscale('log') # Position des ticks ax.set_xticks([0, 1, 2, 3, 4, 5]) ax.set_yticks(np.arange(0, 6, 0.5)) # Labels personnalisés ax.set_xticklabels(['Zero', 'Un', 'Deux', 'Trois', 'Quatre', 'Cinq']) # Rotation des labels plt.xticks(rotation=45) # Enlever les bordures supérieure et droite (style "spine") ax.spines['top'].set_visible(False) ax.spines['right'].set_visible(False) plt.show()
Légendes
[!bug]- Code
import matplotlib.pyplot as plt import numpy as np x = np.linspace(0, 10, 100) plt.figure(figsize=(10, 6)) plt.plot(x, np.sin(x), label='sin(x)', linewidth=2) plt.plot(x, np.cos(x), label='cos(x)', linewidth=2) plt.plot(x, np.sin(x) * np.cos(x), label='sin(x)×cos(x)', linewidth=2) # Légende personnalisée plt.legend( loc='upper right', # Options: 'best', 'upper left', 'lower center', etc. frameon=True, shadow=True, fancybox=True, framealpha=0.9, borderpad=1, title='Fonctions trigonométriques', title_fontsize=12 ) plt.title('Personnalisation de la légende') plt.xlabel('x') plt.ylabel('y') plt.grid(True, alpha=0.3) plt.show()
[!bug]- Légende en dehors du graphique
plt.figure(figsize=(12, 6)) plt.plot(x, np.sin(x), label='sin(x)') plt.plot(x, np.cos(x), label='cos(x)') plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left') plt.tight_layout() plt.show()
Taille et résolution
[!bug]- Code
import matplotlib.pyplot as plt # Contrôle de la taille fig = plt.figure(figsize=(12, 8), dpi=100) # dpi = résolution plt.plot([1, 2, 3], [1, 4, 9]) # Sauvegarder en haute résolution plt.savefig('mon_graphique.png', dpi=300, bbox_inches='tight', facecolor='white', edgecolor='none') # Différents formats plt.savefig('mon_graphique.pdf', bbox_inches='tight') # Vectoriel plt.savefig('mon_graphique.svg', bbox_inches='tight') # Vectoriel plt.show()
Subplots
We use matplotlib frequently to make subplots (also in combination with other libraries)
A Figure in matplotlib means the whole window in the UI. Within this figure there can be several Axes. Subplots are arranged and numbered in a (nrow, ncol) grid as below (think about it as a sheet of paper):

One way of doing this: defining everything sequentially (the “state-based” approach)
[!bug]- Code
fig = plt.figure(figsize=(10, 3)) # Create a `Figure`, your canvas plt.subplot(1, 2, 1) # Start a first subplot plt.plot(france_df.index, france_df['oil_co2']) plt.title('oil_co2') plt.subplot(1, 2, 2) # Start a second subplot plt.plot(france_df.index, france_df['gas_co2']) plt.title('gas_co2');

With the object oriented approach:
[!bug]- Code
fig, axs = plt.subplots(1, 2, figsize=(10, 3)) # Create a `Figure`, your canvas, with (1, 2) being one line two columns axs[0].plot(france_df.index, france_df['oil_co2']) axs[0].set_title('oil_co2') axs[1].plot(france_df.index, france_df['gas_co2']) axs[1].set_title('gas_co2');
On peut utiliser une for loop pour faire un grand nombre de plots !
[!bug]- Code
import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec import numpy as np # Méthode 1 : subplot classique fig, axes = plt.subplots(2, 3, figsize=(15, 10)) fig.suptitle('Multiple subplots', fontsize=16, fontweight='bold') for i, ax in enumerate(axes.flat): ax.plot(np.random.rand(10)) ax.set_title(f'Subplot {i+1}') ax.grid(True, alpha=0.3) plt.tight_layout() plt.show() # Méthode 2 : GridSpec pour layouts complexes fig = plt.figure(figsize=(12, 8)) gs = gridspec.GridSpec(3, 3, figure=fig, hspace=0.3, wspace=0.3) ax1 = fig.add_subplot(gs[0, :]) # Première ligne complète ax2 = fig.add_subplot(gs[1, :-1]) # Deuxième ligne, 2 premières colonnes ax3 = fig.add_subplot(gs[1:, -1]) # Dernière colonne, 2 dernières lignes ax4 = fig.add_subplot(gs[-1, 0]) # Coin inférieur gauche ax5 = fig.add_subplot(gs[-1, 1]) # Coin inférieur centre for ax in [ax1, ax2, ax3, ax4, ax5]: ax.plot(np.random.rand(10)) ax.grid(True, alpha=0.3) plt.show()
Annotations et flèches
[!bug]- Code
import matplotlib.pyplot as plt import numpy as np x = np.linspace(0, 10, 100) y = np.sin(x) fig, ax = plt.subplots(figsize=(12, 6)) ax.plot(x, y, linewidth=2) # Annotation simple ax.annotate('Maximum local', xy=(np.pi/2, 1), xytext=(2, 1.3), arrowprops=dict(arrowstyle='->', connectionstyle='arc3,rad=.2', lw=2, color='red'), fontsize=12, bbox=dict(boxstyle='round,pad=0.5', facecolor='yellow', alpha=0.7)) # Ligne verticale ax.axvline(x=np.pi/2, color='red', linestyle='--', alpha=0.5, label='x = π/2') # Ligne horizontale ax.axhline(y=0, color='gray', linestyle='-', alpha=0.3) # Zone colorée ax.axvspan(6, 8, alpha=0.2, color='green', label='Zone d\'intérêt') # Flèche directe ax.arrow(7, -0.5, 0, 0.8, head_width=0.2, head_length=0.1, fc='blue', ec='blue') plt.legend() plt.grid(True, alpha=0.3) plt.title('Annotations et marqueurs') plt.show()
Styles de lignes et marqueurs
[!bug]- Code
import matplotlib.pyplot as plt import numpy as np x = np.linspace(0, 10, 20) plt.figure(figsize=(12, 8)) # Différents styles styles = [ ('solid', '-', 'o'), ('dashed', '--', 's'), ('dashdot', '-.', '^'), ('dotted', ':', 'D'), ] for i, (nom, style_ligne, marqueur) in enumerate(styles): plt.plot(x, x + i, linestyle=style_ligne, marker=marqueur, markersize=8, markerfacecolor='white', markeredgewidth=2, linewidth=2, label=f'{nom}', alpha=0.8) plt.legend() plt.grid(True, alpha=0.3) plt.title('Styles de lignes et marqueurs') plt.xlabel('X') plt.ylabel('Y') plt.show()
Marqueurs disponibles :
marqueurs = ['o', 's', '^', 'v', '<', '>', 'D', 'p', '*', 'h', 'H', '+', 'x', 'd', '|', '_']
Exemple : graphique type publication
[!bug]- Code
import matplotlib.pyplot as plt import numpy as np import seaborn as sns # Configuration du style sns.set_style("whitegrid") plt.rcParams.update({ 'font.size': 11, 'axes.labelsize': 12, 'axes.titlesize': 14, 'xtick.labelsize': 10, 'ytick.labelsize': 10, 'legend.fontsize': 10, 'figure.titlesize': 16 }) # Données x = np.linspace(0, 10, 100) y1 = np.sin(x) y2 = np.sin(x + np.pi/4) y3 = np.sin(x + np.pi/2) # Création de la figure fig, ax = plt.subplots(figsize=(10, 6), dpi=100) # Tracés avec personnalisation ax.plot(x, y1, linewidth=2.5, label='Condition A', color='#2E86AB', alpha=0.8) ax.plot(x, y2, linewidth=2.5, label='Condition B', color='#A23B72', alpha=0.8) ax.plot(x, y3, linewidth=2.5, label='Condition C', color='#F18F01', alpha=0.8) # Remplissage sous la courbe ax.fill_between(x, 0, y1, alpha=0.1, color='#2E86AB') # Personnalisation des axes ax.set_xlabel('Temps (s)', fontweight='bold') ax.set_ylabel('Amplitude (u.a.)', fontweight='bold') ax.set_title('Évolution temporelle des oscillations', fontweight='bold', pad=20) # Grille personnalisée ax.grid(True, linestyle='--', linewidth=0.5, alpha=0.7) ax.set_axisbelow(True) # Grille en arrière-plan # Supprimer les bordures supérieure et droite ax.spines['top'].set_visible(False) ax.spines['right'].set_visible(False) # Légende ax.legend(loc='upper right', frameon=True, shadow=True, framealpha=0.95, edgecolor='gray') # Annotation d'un point d'intérêt max_idx = np.argmax(y1) ax.annotate(f'Maximum\n({x[max_idx]:.2f}, {y1[max_idx]:.2f})', xy=(x[max_idx], y1[max_idx]), xytext=(7, 0.7), arrowprops=dict(arrowstyle='->', lw=1.5, color='black'), fontsize=10, bbox=dict(boxstyle='round,pad=0.5', facecolor='white', edgecolor='gray', alpha=0.9)) plt.tight_layout() # Sauvegarder plt.savefig('graphique_publication.png', dpi=300, bbox_inches='tight', facecolor='white') plt.show()
Seaborn
hue
Le paramètre hue ajoute une troisième dimension en colorant selon une variable catégorielle.
→ distinguer différentes familles de molécules, conditions expérimentales, etc.
[!bug]- Code
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np # Données simulées : propriétés de molécules np.random.seed(42) df_molecules = pd.DataFrame({ 'masse_moleculaire': np.random.normal(250, 50, 200), 'logP': np.random.normal(2.5, 1.5, 200), 'solubilite': np.random.normal(50, 20, 200), 'famille': np.random.choice(['Alcane', 'Alcool', 'Amine', 'Ester'], 200), 'activite': np.random.choice(['Active', 'Inactive'], 200) }) # Scatterplot avec hue plt.figure(figsize=(12, 6)) sns.scatterplot(data=df_molecules, x='masse_moleculaire', y='logP', hue='famille', # Couleur par famille style='activite', # Forme par activité s=100, # Taille des points alpha=0.7) plt.title('Distribution des propriétés physico-chimiques') plt.xlabel('Masse moléculaire (g/mol)') plt.ylabel('LogP (coefficient de partition)') plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left') plt.tight_layout() plt.show()
Combinaison hue + size :
# Ajout d'une 4ème dimension avec la taille
plt.figure(figsize=(12, 6))
sns.scatterplot(data=df_molecules,
x='masse_moleculaire',
y='logP',
hue='famille',
size='solubility', # Taille proportionnelle à la solubilité
sizes=(20, 200),
alpha=0.6)
plt.title('Propriétés multidimensionnelles des composés')
plt.tight_layout()
plt.show()
Countplot : distributions catégorielles
Parfait pour visualiser la répartition des échantillons, le succès/échec de réactions, etc.

[!bug]- Code
# Données de screening chimique df_screening = pd.DataFrame({ 'catalyseur': np.random.choice(['Pd', 'Pt', 'Ru', 'Ni'], 300), 'solvant': np.random.choice(['THF', 'DCM', 'Toluene', 'EtOH'], 300), 'resultat': np.random.choice(['Succès', 'Échec'], 300, p=[0.6, 0.4]) }) # Countplot simple plt.figure(figsize=(10, 6)) sns.countplot(data=df_screening, x='catalyseur', hue='resultat') plt.title('Taux de succès par catalyseur') plt.ylabel('Nombre d\'expériences') plt.show() # Countplot horizontal avec ordre personnalisé plt.figure(figsize=(10, 6)) ordre_catalyseurs = df_screening.groupby('catalyseur').size().sort_values(ascending=False).index sns.countplot(data=df_screening, y='catalyseur', hue='resultat', order=ordre_catalyseurs, palette='viridis') plt.title('Distribution des essais par catalyseur') plt.xlabel('Nombre d\'expériences') plt.tight_layout() plt.show()
Catplot : facettes multiples
Comparer plusieurs conditions simultanément (plans d’expériences)

[!bug]- Code
# Plan d'expérience : température vs rendement df_doe = pd.DataFrame({ 'temperature': np.random.normal(80, 20, 200), 'rendement': np.random.normal(70, 15, 200), 'catalyseur': np.random.choice(['Pd', 'Pt', 'Ru'], 200), 'solvant': np.random.choice(['THF', 'DCM'], 200) }) # FacetGrid automatique avec catplot sns.catplot(data=df_doe, x='catalyseur', y='rendement', hue='solvant', col='solvant', # Colonnes séparées par solvant kind='box', # Options: 'strip', 'swarm', 'box', 'violin', 'boxen', 'point', 'bar' height=5, aspect=1.2) plt.suptitle('Rendement en fonction du catalyseur et du solvant', y=1.02) plt.tight_layout() plt.show()
Avec relplot (relation plots) :
sns.relplot(data=df_doe,
x='temperature',
y='rendement',
hue='catalyseur',
col='solvant', # Facette par solvant
kind='scatter', # ou 'line'
height=5,
aspect=1.2,
alpha=0.6)
plt.suptitle('Effet de la température sur le rendement', y=1.02)
plt.tight_layout()
plt.show()
Pairplot : matrice de corrélations
Explorer les relations entre variables (ex. descripteurs moléculaires)
The kind parameter determines both the diagonal and off-diagonal plotting style. Several options are available, including using kdeplot() to draw KDEs:
[!bug]- Code
# Descripteurs moléculaires df_descripteurs = pd.DataFrame({ 'MW': np.random.normal(300, 80, 150), # Masse moléculaire 'LogP': np.random.normal(2.5, 1.2, 150), # Lipophilie 'HBD': np.random.poisson(2, 150), # Donneurs de liaisons H 'HBA': np.random.poisson(4, 150), # Accepteurs de liaisons H 'PSA': np.random.normal(80, 30, 150), # Surface polaire 'Classe': np.random.choice(['Drug-like', 'Lead-like', 'Fragment'], 150) }) # Pairplot complet sns.pairplot(df_descripteurs, hue='Classe', diag_kind='kde', # Histogrammes en densité sur la diagonale plot_kws={'alpha': 0.6, 's': 50}, corner=False) # corner=True pour afficher seulement la moitié inférieure plt.suptitle('Matrice de corrélations des descripteurs moléculaires', y=1.01) plt.tight_layout() plt.show() # Pairplot sur variables sélectionnées sns.pairplot(df_descripteurs, vars=['MW', 'LogP', 'PSA'], # Sélection de variables hue='Classe', diag_kind='hist') plt.tight_layout() plt.show()
Heatmap : matrices de corrélation et plus
Visualisation da matrices de similarité, corrélations entre descripteurs, résultats de criblage…
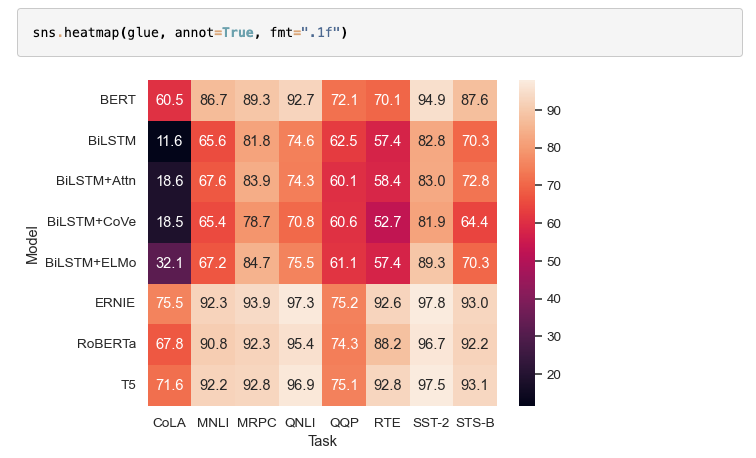
[!bug]- Code
# Matrice de corrélation plt.figure(figsize=(10, 8)) correlation_matrix = df_descripteurs[['MW', 'LogP', 'HBD', 'HBA', 'PSA']].corr() sns.heatmap(correlation_matrix, annot=True, # Afficher les valeurs fmt='.2f', # Format des nombres cmap='coolwarm', # Palette divergente center=0, # Centrer sur 0 square=True, linewidths=1, cbar_kws={'label': 'Coefficient de corrélation'}) plt.title('Corrélations entre descripteurs moléculaires') plt.tight_layout() plt.show() # Heatmap de données : criblage haut débit # Simulation de données IC50 pour différentes molécules vs cibles molecules = [f'Mol_{i}' for i in range(1, 21)] cibles = [f'Cible_{j}' for j in range(1, 11)] ic50_data = np.random.lognormal(0, 2, (20, 10)) df_ic50 = pd.DataFrame(ic50_data, index=molecules, columns=cibles) plt.figure(figsize=(12, 10)) sns.heatmap(df_ic50, cmap='YlOrRd', # Jaune-Orange-Rouge cbar_kws={'label': 'IC50 (μM)'}, linewidths=0.5, fmt='.1f') plt.title('Criblage d\'activité : IC50 des molécules sur différentes cibles') plt.xlabel('Cibles biologiques') plt.ylabel('Molécules testées') plt.tight_layout() plt.show()
Jointplot : distribution bivariée détaillée
Pour examiner en détail la relation entre deux variables importantes.

[!bug]- Code
# Relation entre deux propriétés clés plt.figure(figsize=(10, 10)) sns.jointplot(data=df_descripteurs, x='MW', y='LogP', hue='Classe', kind='scatter', # Options: 'scatter', 'kde', 'hist', 'hex', 'reg', 'resid' alpha=0.6, height=8) plt.suptitle('Distribution bivariée MW vs LogP', y=1.02) plt.tight_layout() plt.show() # Avec régression sns.jointplot(data=df_descripteurs, x='MW', y='PSA', kind='reg', # Ajoute une régression linéaire height=8, color='purple') plt.tight_layout() plt.show()
Violinplot et Swarmplot : distributions détaillées
Parfait pour comparer les distributions de variables (ex. rendements, énergies, etc.)
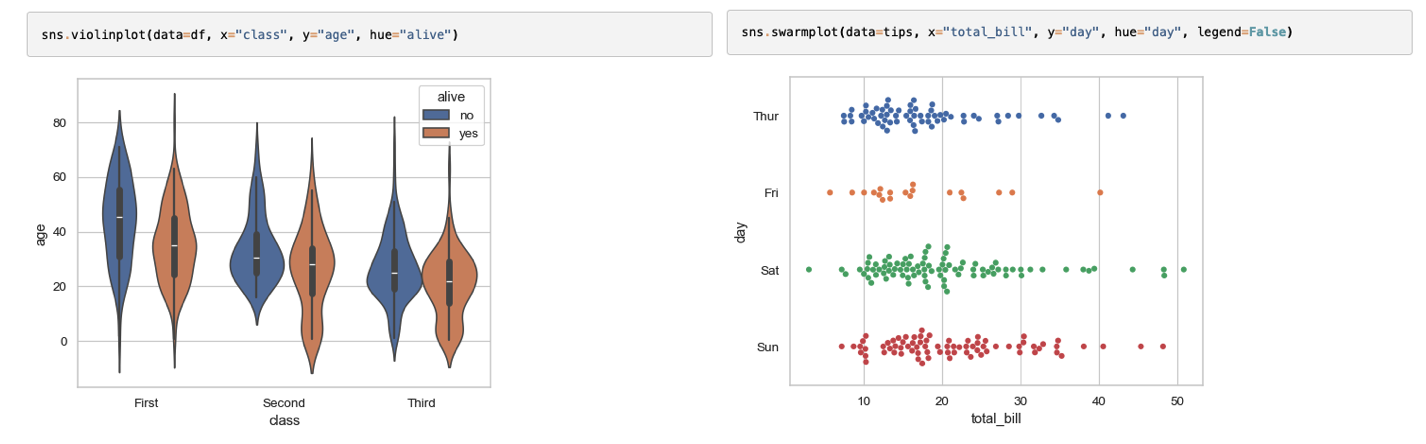
[!bug]- Code
# Données cinétiques df_cinetique = pd.DataFrame({ 'temps_reaction': np.concatenate([ np.random.gamma(2, 2, 50), np.random.gamma(3, 1.5, 50), np.random.gamma(4, 1, 50) ]), 'temperature': ['60°C']*50 + ['80°C']*50 + ['100°C']*50, 'catalyseur': np.random.choice(['Pd', 'Pt'], 150) }) # Violinplot plt.figure(figsize=(12, 6)) sns.violinplot(data=df_cinetique, x='temperature', y='temps_reaction', hue='catalyseur', split=True, # Divise le violin pour comparer 2 hues inner='quartile', # Affiche les quartiles palette='muted') plt.title('Distribution des temps de réaction') plt.ylabel('Temps de réaction (h)') plt.tight_layout() plt.show() # Swarmplot superposé (attention : ne pas utiliser avec trop de données !) plt.figure(figsize=(12, 6)) sns.violinplot(data=df_cinetique, x='temperature', y='temps_reaction', hue='catalyseur', alpha=0.6) sns.swarmplot(data=df_cinetique, x='temperature', y='temps_reaction', hue='catalyseur', dodge=True, # Séparer par hue size=3, alpha=0.8, legend=False) plt.title('Distribution des temps de réaction avec points individuels') plt.tight_layout() plt.show()
Regplot et lmplot : régressions
Pour visualiser les relations linéaires et tendances.
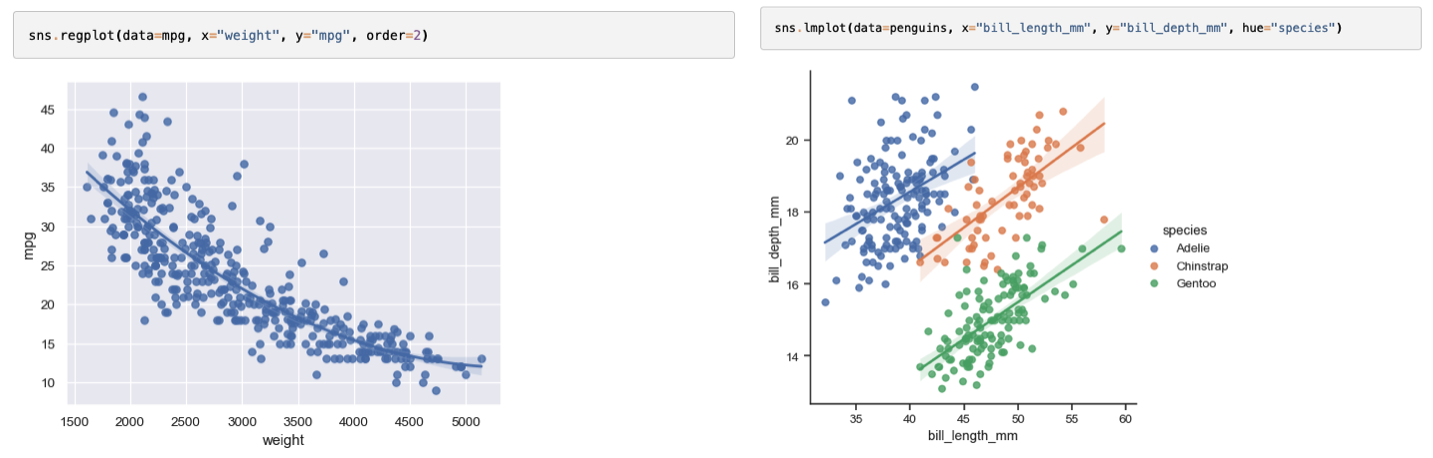
[!bug]- Code
# Régression simple plt.figure(figsize=(10, 6)) sns.regplot(data=df_descripteurs, x='MW', y='PSA', scatter_kws={'alpha': 0.5, 's': 50}, line_kws={'color': 'red', 'linewidth': 2}) plt.title('Régression linéaire : PSA vs MW') plt.xlabel('Masse moléculaire (g/mol)') plt.ylabel('Surface polaire (Ų)') plt.tight_layout() plt.show() # lmplot avec facettes sns.lmplot(data=df_doe, x='temperature', y='rendement', hue='catalyseur', col='solvant', height=5, aspect=1.2, scatter_kws={'alpha': 0.5}) plt.suptitle('Régression rendement vs température', y=1.02) plt.tight_layout() plt.show()
Applications en Chemical Data Science
[!example]- Visualisation de l’espace chimique
# Projection 2D de l'espace chimique (simulation) from sklearn.decomposition import PCA # Descripteurs moléculaires multiples X = df_descripteurs[['MW', 'LogP', 'HBD', 'HBA', 'PSA']].values pca = PCA(n_components=2) X_pca = pca.fit_transform(X) df_pca = pd.DataFrame({ 'PC1': X_pca[:, 0], 'PC2': X_pca[:, 1], 'Classe': df_descripteurs['Classe'] }) plt.figure(figsize=(12, 8)) sns.scatterplot(data=df_pca, x='PC1', y='PC2', hue='Classe', s=100, alpha=0.7, palette='Set2') plt.title(f'Espace chimique (PCA)\nVariance expliquée: PC1={pca.explained_variance_ratio_[0]:.1%}, PC2={pca.explained_variance_ratio_[1]:.1%}') plt.xlabel(f'PC1 ({pca.explained_variance_ratio_[0]:.1%})') plt.ylabel(f'PC2 ({pca.explained_variance_ratio_[1]:.1%})') # Ajouter des ellipses de confiance from matplotlib.patches import Ellipse for classe in df_pca['Classe'].unique(): subset = df_pca[df_pca['Classe'] == classe] mean_x, mean_y = subset['PC1'].mean(), subset['PC2'].mean() std_x, std_y = subset['PC1'].std(), subset['PC2'].std() ellipse = Ellipse((mean_x, mean_y), width=2*std_x, height=2*std_y, fill=False, linestyle='--', linewidth=2, alpha=0.5) plt.gca().add_patch(ellipse) plt.tight_layout() plt.show()
[!example]- Diagramme de Lipinski (Rule of Five)
# Visualisation des règles de Lipinski fig, axes = plt.subplots(2, 2, figsize=(14, 12)) # MW ≤ 500 sns.histplot(data=df_descripteurs, x='MW', hue='Classe', kde=True, ax=axes[0, 0]) axes[0, 0].axvline(x=500, color='red', linestyle='--', linewidth=2, label='Limite Lipinski') axes[0, 0].set_title('Distribution de la masse moléculaire') axes[0, 0].legend() # LogP ≤ 5 sns.histplot(data=df_descripteurs, x='LogP', hue='Classe', kde=True, ax=axes[0, 1]) axes[0, 1].axvline(x=5, color='red', linestyle='--', linewidth=2, label='Limite Lipinski') axes[0, 1].set_title('Distribution du LogP') axes[0, 1].legend() # HBD ≤ 5 sns.histplot(data=df_descripteurs, x='HBD', hue='Classe', discrete=True, ax=axes[1, 0]) axes[1, 0].axvline(x=5.5, color='red', linestyle='--', linewidth=2, label='Limite Lipinski') axes[1, 0].set_title('Donneurs de liaisons H') axes[1, 0].legend() # HBA ≤ 10 sns.histplot(data=df_descripteurs, x='HBA', hue='Classe', discrete=True, ax=axes[1, 1]) axes[1, 1].axvline(x=10.5, color='red', linestyle='--', linewidth=2, label='Limite Lipinski') axes[1, 1].set_title('Accepteurs de liaisons H') axes[1, 1].legend() plt.suptitle('Analyse selon les règles de Lipinski (Rule of Five)', fontsize=16, fontweight='bold') plt.tight_layout() plt.show()
[!example]- Structure-Activity Relationship (SAR)
# Visualisation SAR df_sar = pd.DataFrame({ 'substituant': ['H', 'CH3', 'OCH3', 'Cl', 'Br', 'CF3', 'NO2', 'NH2'], 'IC50_uM': [15.2, 8.5, 3.2, 6.8, 5.1, 12.3, 18.7, 2.8], 'sigma_hammett': [0, -0.17, -0.27, 0.23, 0.23, 0.54, 0.78, -0.66], 'serie': ['Serie_A', 'Serie_A', 'Serie_A', 'Serie_B', 'Serie_B', 'Serie_B', 'Serie_C', 'Serie_C'] }) fig, axes = plt.subplots(1, 2, figsize=(16, 6)) # Barplot IC50 sns.barplot(data=df_sar, x='substituant', y='IC50_uM', hue='serie', ax=axes[0]) axes[0].set_ylabel('IC50 (μM)', fontweight='bold') axes[0].set_xlabel('Substituant', fontweight='bold') axes[0].set_title('Activité biologique par substituant', fontweight='bold') axes[0].axhline(y=10, color='red', linestyle='--', alpha=0.5, label='Seuil d\'activité') axes[0].legend() # Corrélation Hammett sns.scatterplot(data=df_sar, x='sigma_hammett', y='IC50_uM', hue='serie', s=150, ax=axes[1]) sns.regplot(data=df_sar, x='sigma_hammett', y='IC50_uM', scatter=False, color='gray', ax=axes[1]) # Annoter chaque point for idx, row in df_sar.iterrows(): axes[1].annotate(row['substituant'], (row['sigma_hammett'], row['IC50_uM']), xytext=(5, 5), textcoords='offset points', fontsize=9) axes[1].set_xlabel('σ de Hammett', fontweight='bold') axes[1].set_ylabel('IC50 (μM)', fontweight='bold') axes[1].set_title('Corrélation électronique (Hammett)', fontweight='bold') plt.tight_layout() plt.show()
[!example]- Clustermap : dendrogramme + heatmap
# Clustering hiérarchique de molécules basé sur la similarité plt.figure(figsize=(12, 10)) # Normaliser les données from sklearn.preprocessing import StandardScaler df_norm = df_descripteurs[['MW', 'LogP', 'HBD', 'HBA', 'PSA']].copy() scaler = StandardScaler() df_norm_scaled = pd.DataFrame( scaler.fit_transform(df_norm), columns=df_norm.columns, index=df_norm.index ) # Clustermap sns.clustermap(df_norm_scaled.iloc[:30], # Sous-ensemble pour lisibilité cmap='vlag', center=0, figsize=(12, 10), dendrogram_ratio=0.15, cbar_pos=(0.02, 0.83, 0.03, 0.15), linewidths=0.5, method='ward', # Méthode de clustering metric='euclidean') # Métrique de distance plt.suptitle('Clustering hiérarchique des molécules\nbasé sur les descripteurs normalisés', y=0.98, fontweight='bold') plt.show()
[!example]- Palettes de couleurs personnalisées pour la chimie
# Palettes inspirées de la chimie palette_elements = { 'C': '#909090', # Carbone - gris 'N': '#3050F8', # Azote - bleu 'O': '#FF0D0D', # Oxygène - rouge 'S': '#FFFF30', # Soufre - jaune 'P': '#FF8000', # Phosphore - orange 'Hal': '#1FFF00' # Halogène - vert } # Palette pour niveaux d'énergie / états palette_energie = ['#2C3E50', '#3498DB', '#1ABC9C', '#F39C12', '#E74C3C'] # Palette température (froid → chaud) palette_temp = sns.color_palette("coolwarm", as_cmap=False) # Application df_elements = pd.DataFrame({ 'element': ['C', 'N', 'O', 'S', 'P', 'Hal'], 'count': [45, 12, 8, 3, 2, 5] }) plt.figure(figsize=(10, 6)) sns.barplot(data=df_elements, x='element', y='count', palette=list(palette_elements.values())) plt.title('Distribution des atomes dans la molécule', fontweight='bold') plt.ylabel('Nombre d\'atomes') plt.xlabel('Élément') plt.tight_layout() plt.show()
Plotly Express
[!NOTE] Initialisation
import plotly.express as px import pandas as pd import numpy as np # Données exemple df_mol = pd.DataFrame({ 'MW': np.random.normal(350, 100, 200), 'LogP': np.random.normal(2.5, 1.5, 200), 'PSA': np.random.normal(70, 25, 200), 'HBD': np.random.poisson(2, 200), 'Activity': np.random.choice(['High', 'Medium', 'Low'], 200), 'Molecule_ID': [f'MOL_{i:03d}' for i in range(200)], 'Series': np.random.choice(['A', 'B', 'C'], 200) }) # Premier graphique interactif fig = px.scatter(df_mol, x='MW', y='LogP', color='Activity', size='PSA', hover_data=['Molecule_ID', 'HBD'], # Info au survol title='Espace chimique interactif') # Personnalisation fig.update_layout( font=dict(size=12), hovermode='closest', plot_bgcolor='white' ) fig.update_xaxes(showgrid=True, gridwidth=1, gridcolor='lightgray') fig.update_yaxes(showgrid=True, gridwidth=1, gridcolor='lightgray') fig.show()
Scatter 3D : visualisation de données dans l’espace
→ exploration de l’espace chimique
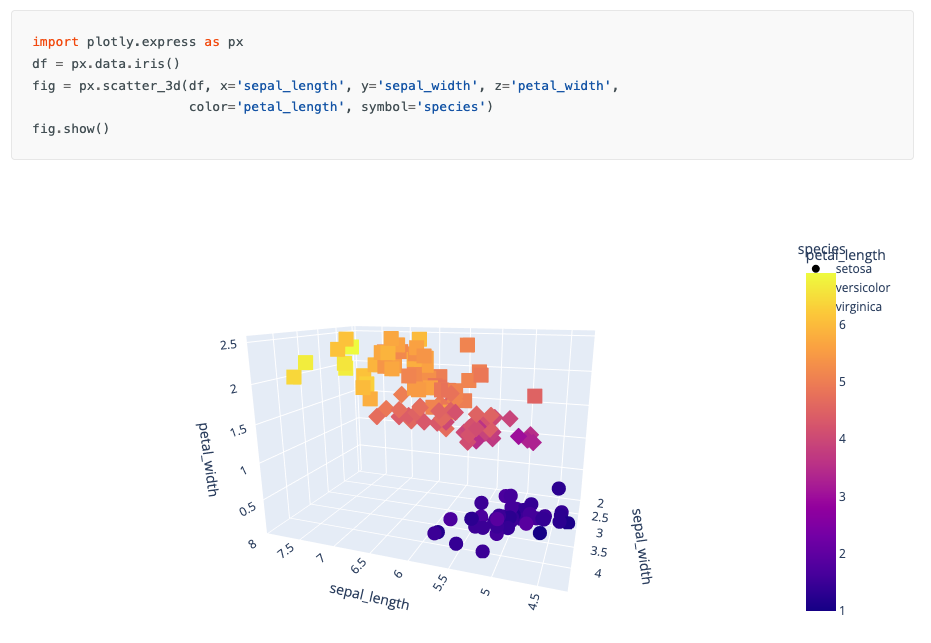
[!bug]- Code
# Visualisation 3D de l'espace chimique fig = px.scatter_3d(df_mol, x='MW', y='LogP', z='PSA', color='Activity', size='HBD', hover_name='Molecule_ID', symbol='Series', title='Espace chimique 3D', labels={ 'MW': 'Masse moléculaire (g/mol)', 'LogP': 'Coefficient de partition', 'PSA': 'Surface polaire (Ų)' }, color_discrete_map={ 'High': '#00CC96', 'Medium': '#FFA15A', 'Low': '#EF553B' }) fig.update_layout( scene=dict( xaxis_title='MW (g/mol)', yaxis_title='LogP', zaxis_title='PSA (Ų)', bgcolor='rgba(240,240,240,0.9)' ), height=700 ) fig.show()
Parallel coordinates : comparaison multivariée
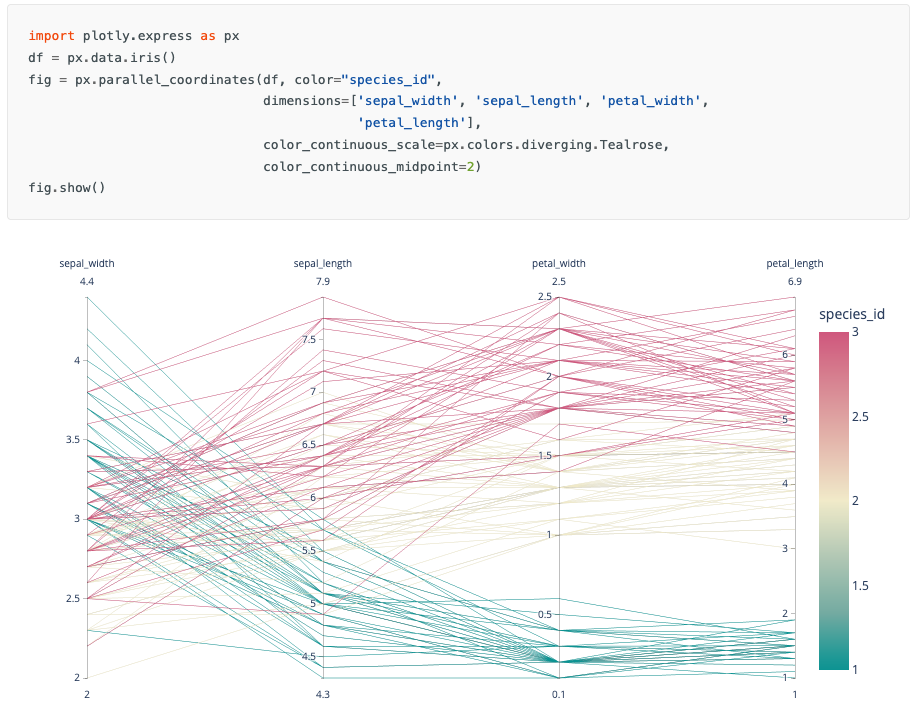
[!bug]- Code
# Filtrer pour plus de clarté df_subset = df_mol[df_mol['Activity'].isin(['High', 'Low'])].copy() fig = px.parallel_coordinates( df_subset, dimensions=['MW', 'LogP', 'PSA', 'HBD'], color='Activity', color_discrete_map={'High': 'green', 'Low': 'red'}, title='Coordonnées parallèles : Profil des molécules actives vs inactives', labels={ 'MW': 'MW', 'LogP': 'LogP', 'PSA': 'PSA', 'HBD': 'HBD' } ) fig.update_layout(height=600) fig.show()
Parallel categories : Flux entre catégories
Pour visualiser les relations entre variables catégorielles (screening, classification…)
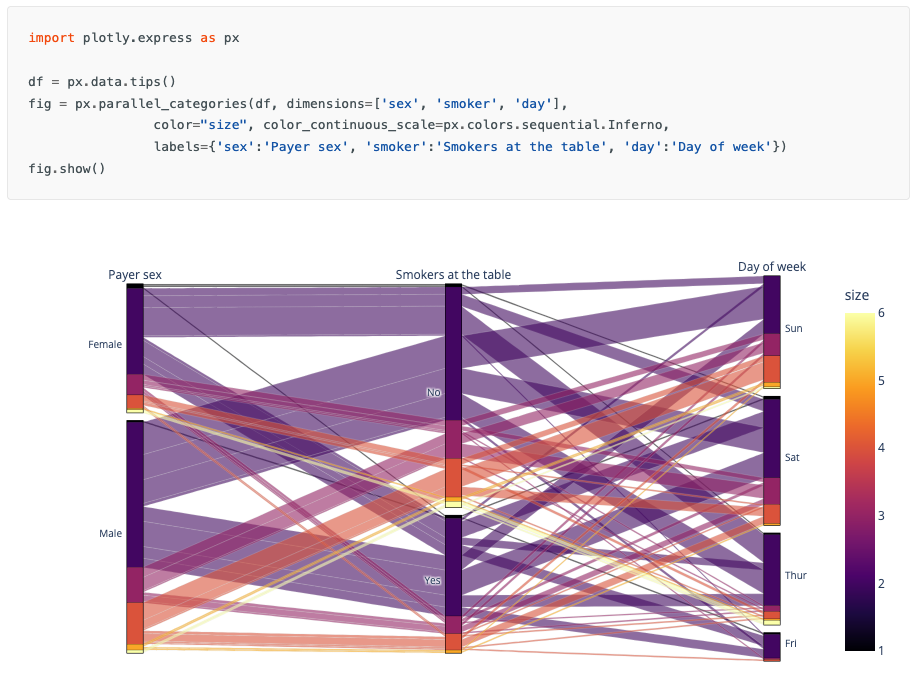
[!bug]- Code
# Données de screening df_screening_flow = pd.DataFrame({ 'Catalyseur': np.random.choice(['Pd', 'Pt', 'Ru', 'Ni'], 300), 'Solvant': np.random.choice(['THF', 'DCM', 'Toluene'], 300), 'Temperature': np.random.choice(['RT', '60°C', '80°C'], 300), 'Rendement': np.random.choice(['<30%', '30-70%', '>70%'], 300), 'Count': 1 }) fig = px.parallel_categories( df_screening_flow, dimensions=['Catalyseur', 'Solvant', 'Temperature', 'Rendement'], color='Rendement', color_discrete_map={ '<30%': '#EF553B', '30-70%': '#FFA15A', '>70%': '#00CC96' }, title='Flux des conditions expérimentales vers le rendement' ) fig.update_layout(height=600) fig.show()
Scatter matrix : pairplot interactif
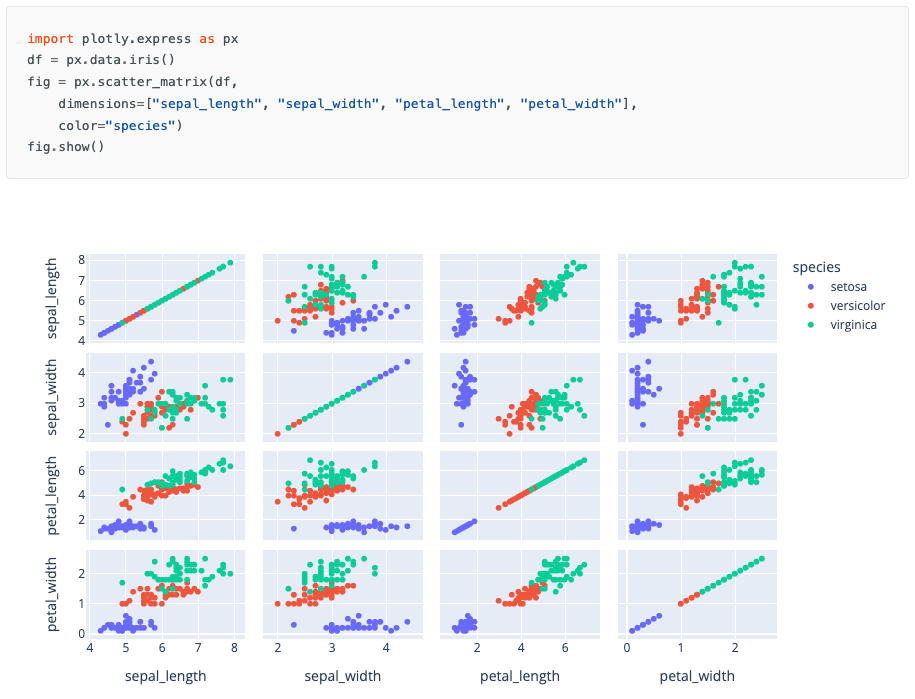
[!bug]- Code
# Matrice de scatter interactive fig = px.scatter_matrix( df_mol, dimensions=['MW', 'LogP', 'PSA', 'HBD'], color='Activity', symbol='Series', title='Matrice de corrélations interactive', height=800 ) fig.update_traces(diagonal_visible=False, showupperhalf=False) fig.show()
Sunburst et Treemap : hiérarchies
Pour visualiser des classifications hiérarchiques (familles chimiques, ontologies…)
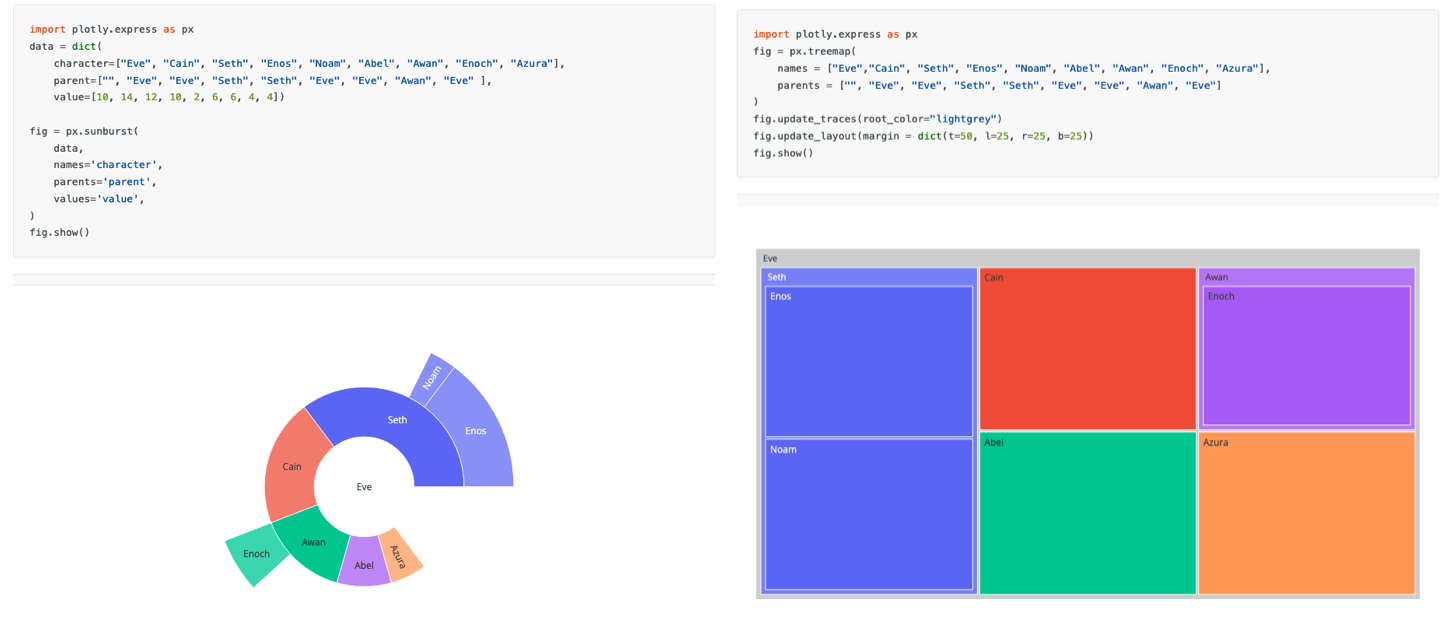
[!bug]- Code
# Données hiérarchiques df_hierarchy = pd.DataFrame({ 'Famille': ['Alcanes', 'Alcanes', 'Alcenes', 'Alcenes', 'Aromatiques', 'Aromatiques', 'Aromatiques', 'Heterocycles', 'Heterocycles', 'Heterocycles'], 'Sous_famille': ['Lineaires', 'Ramifies', 'Terminaux', 'Internes', 'Benzenes', 'Naphthalenes', 'Polycycliques', 'Azotes', 'Oxygenes', 'Soufres'], 'Count': [45, 32, 28, 19, 56, 23, 15, 38, 31, 12], 'MW_moyen': [180, 220, 190, 210, 250, 280, 320, 230, 200, 240] }) # Sunburst fig = px.sunburst( df_hierarchy, path=['Famille', 'Sous_famille'], values='Count', color='MW_moyen', color_continuous_scale='Viridis', title='Classification hiérarchique des composés' ) fig.update_layout(height=700) fig.show() # Treemap fig = px.treemap( df_hierarchy, path=['Famille', 'Sous_famille'], values='Count', color='MW_moyen', color_continuous_scale='RdYlGn_r', title='Distribution des familles chimiques (Treemap)', hover_data=['MW_moyen'] ) fig.update_layout(height=600) fig.show()
Animations : évolution temporelle
Parfait pour suivre l’évolution d’une réaction, d’une cinétique, d’un criblage séquentiel…

[!bug]- Code
# Simulation d'une cinétique de réaction temps = np.linspace(0, 10, 50) df_cinetique_anim = [] for t in temps: for reactif in ['A', 'B', 'C', 'Produit']: if reactif == 'A': conc = 1.0 * np.exp(-0.5 * t) elif reactif == 'B': conc = 0.8 * np.exp(-0.3 * t) elif reactif == 'C': conc = 0.3 * np.exp(-0.2 * t) + 0.2 else: # Produit conc = 1.0 * (1 - np.exp(-0.4 * t)) df_cinetique_anim.append({ 'Temps': t, 'Espece': reactif, 'Concentration': conc }) df_cinetique_anim = pd.DataFrame(df_cinetique_anim) # Animation fig = px.line( df_cinetique_anim, x='Temps', y='Concentration', color='Espece', animation_frame='Temps', range_y=[0, 1.2], title='Cinétique de réaction (animation)', labels={'Temps': 'Temps (h)', 'Concentration': 'Concentration (M)'} ) fig.update_xaxes(range=[0, 10]) fig.update_layout(height=600) # Ralentir l'animation fig.layout.updatemenus[0].buttons[0].args[1]['frame']['duration'] = 100 fig.show()
Heatmap interactive et dendrogramme
[!bug]- Code
# Matrice de similarité Tanimoto (simulée) n_mol = 30 similarity_matrix = np.random.rand(n_mol, n_mol) # Rendre symétrique similarity_matrix = (similarity_matrix + similarity_matrix.T) / 2 np.fill_diagonal(similarity_matrix, 1.0) mol_names = [f'MOL_{i:02d}' for i in range(n_mol)] # Heatmap interactive fig = px.imshow( similarity_matrix, x=mol_names, y=mol_names, color_continuous_scale='Viridis', title='Matrice de similarité Tanimoto', labels=dict(color='Similarité'), aspect='auto' ) fig.update_layout( width=900, height=800, xaxis_title='Molécule', yaxis_title='Molécule' ) fig.show()
Violin plot et box plot
[!bug]- Code
# Données de rendement par conditions df_rendement = pd.DataFrame({ 'Rendement': np.concatenate([ np.random.normal(45, 12, 50), np.random.normal(65, 10, 50), np.random.normal(82, 8, 50), np.random.normal(38, 15, 50), np.random.normal(72, 9, 50), np.random.normal(88, 7, 50) ]), 'Catalyseur': ['Pd']*150 + ['Pt']*150, 'Temperature': ['60°C', '80°C', '100°C']*100 }) # Violin plot fig = px.violin( df_rendement, x='Temperature', y='Rendement', color='Catalyseur', box=True, # Ajouter boxplot à l'intérieur points='all', # Afficher tous les points title='Distribution des rendements par conditions', hover_data=df_rendement.columns ) fig.update_layout(height=600) fig.show() # Box plot avec points fig = px.box( df_rendement, x='Temperature', y='Rendement', color='Catalyseur', points='all', # 'outliers', 'suspectedoutliers', 'all', False notched=True, # Encoche pour visualiser IC title='Boîtes à moustaches avec tous les points' ) fig.update_layout(height=600) fig.show()
Applications en Chemical Data Science
[!example]- Carte de densité 2D
# Densité dans l'espace MW-LogP fig = px.density_contour( df_mol, x='MW', y='LogP', marginal_x='histogram', marginal_y='histogram', title='Densité de l\'espace chimique exploré', labels={'MW': 'Masse moléculaire (g/mol)', 'LogP': 'LogP'} ) fig.update_traces(contours_coloring='fill', contours_showlabels=True) fig.update_layout(height=700) fig.show() # Heatmap 2D (density heatmap) fig = px.density_heatmap( df_mol, x='MW', y='LogP', marginal_x='violin', marginal_y='violin', color_continuous_scale='Viridis', title='Carte de chaleur de densité' ) fig.update_layout(height=700) fig.show()
[!example]- Diagramme de Lipinski interactif
# Analyse des violations de Lipinski df_mol['Lipinski_violations'] = ( (df_mol['MW'] > 500).astype(int) + (df_mol['LogP'] > 5).astype(int) + (df_mol['HBD'] > 5).astype(int) ) df_mol['Drug_like'] = df_mol['Lipinski_violations'].map({ 0: 'Compliant', 1: '1 violation', 2: '2 violations', 3: '3+ violations' }) fig = px.scatter( df_mol, x='MW', y='LogP', color='Drug_like', size='PSA', hover_data=['Molecule_ID', 'HBD', 'PSA'], title='Analyse Drug-likeness (Lipinski)', color_discrete_sequence=['#00CC96', '#FFA15A', '#EF553B', '#AB63FA'] ) # Ajouter lignes de référence Lipinski fig.add_hline(y=5, line_dash='dash', line_color='red', annotation_text='LogP = 5') fig.add_vline(x=500, line_dash='dash', line_color='red', annotation_text='MW = 500') fig.update_layout(height=700) fig.show()
[!example]- Visualisation de trajectoires (MD, Optimization)
# Simulation de trajectoire d'optimisation moléculaire n_steps = 100 df_trajectory = pd.DataFrame({ 'Step': np.repeat(range(n_steps), 3), 'Coordinate': ['X', 'Y', 'Z'] * n_steps, 'Value': np.concatenate([ np.cumsum(np.random.randn(n_steps)) * 0.1, # X np.cumsum(np.random.randn(n_steps)) * 0.1, # Y np.cumsum(np.random.randn(n_steps)) * 0.1 # Z ]), 'Energy': np.repeat(1000 - np.arange(n_steps) * 5 + np.random.randn(n_steps) * 10, 3) }) fig = px.line_3d( df_trajectory[df_trajectory['Coordinate'] == 'X'].reset_index(), x=df_trajectory[df_trajectory['Coordinate'] == 'X']['Value'].values, y=df_trajectory[df_trajectory['Coordinate'] == 'Y']['Value'].values, z=df_trajectory[df_trajectory['Coordinate'] == 'Z']['Value'].values, color=df_trajectory[df_trajectory['Coordinate'] == 'X']['Energy'].values, title='Trajectoire d\'optimisation géométrique', labels={'color': 'Énergie (kJ/mol)'}, color_continuous_scale='Rainbow' ) fig.update_layout( scene=dict( xaxis_title='X (Å)', yaxis_title='Y (Å)', zaxis_title='Z (Å)' ), height=700 ) fig.show()
[!example]- Diagramme de corrélation avec régression
# Corrélation prédictive df_prediction = pd.DataFrame({ 'Experimental_IC50': np.random.lognormal(1, 1, 100), 'Predicted_IC50': np.random.lognormal(1, 1, 100) * 1.2 + np.random.randn(100) * 0.3, 'Model': np.random.choice(['Random Forest', 'XGBoost', 'Neural Net'], 100), 'Molecule_ID': [f'MOL_{i:03d}' for i in range(100)] }) fig = px.scatter( df_prediction, x='Experimental_IC50', y='Predicted_IC50', color='Model', trendline='ols', # Ajoute ligne de régression hover_data=['Molecule_ID'], title='Validation du modèle prédictif (IC50)', labels={ 'Experimental_IC50': 'IC50 expérimental (μM)', 'Predicted_IC50': 'IC50 prédit (μM)' } ) # Ajouter ligne d'identité import plotly.graph_objects as go max_val = max(df_prediction['Experimental_IC50'].max(), df_prediction['Predicted_IC50'].max()) fig.add_trace( go.Scatter( x=[0, max_val], y=[0, max_val], mode='lines', name='Identité', line=dict(color='red', dash='dash') ) ) fig.update_layout(height=700) fig.show()
[!bug]- Surface de réponse (Response Surface)
# Plan d'expériences - surface de réponse from scipy.interpolate import griddata # Données DoE temp_range = np.random.uniform(50, 100, 30) conc_range = np.random.uniform(0.1, 1.0, 30) rendement = 50 + 0.5*temp_range + 20*conc_range - 0.3*temp_range*conc_range + np.random.randn(30)*5 df_doe = pd.DataFrame({ 'Temperature': temp_range, 'Concentration': conc_range, 'Rendement': rendement }) # Créer grille interpolée temp_grid = np.linspace(50, 100, 50) conc_grid = np.linspace(0.1, 1.0, 50) temp_mesh, conc_mesh = np.meshgrid(temp_grid, conc_grid) rendement_interp = griddata( (df_doe['Temperature'], df_doe['Concentration']), df_doe['Rendement'], (temp_mesh, conc_mesh), method='cubic' ) # Surface 3D fig = go.Figure(data=[ go.Surface( x=temp_grid, y=conc_grid, z=rendement_interp, colorscale='Viridis', name='Surface de réponse' ) ]) # Ajouter points expérimentaux fig.add_trace( go.Scatter3d( x=df_doe['Temperature'], y=df_doe['Concentration'], z=df_doe['Rendement'], mode='markers', marker=dict(size=6, color='red'), name='Points expérimentaux' ) ) fig.update_layout( title='Surface de réponse : Rendement vs Température & Concentration', scene=dict( xaxis_title='Température (°C)', yaxis_title='Concentration (M)', zaxis_title='Rendement (%)' ), height=700 ) fig.show()
Templates
import plotly.io as pio
import plotly.graph_objects as go
# Créer un template personnalisé pour la chimie
chemistry_template = go.layout.Template()
chemistry_template.layout = dict(
font=dict(family='Arial', size=12, color='#2C3E50'),
title=dict(font=dict(size=18, color='#2C3E50'), x=0.5, xanchor='center'),
plot_bgcolor='white',
paper_bgcolor='white',
colorway=['#3498DB', '#E74C3C', '#2ECC71', '#F39C12', '#9B59B6', '#1ABC9C'],
hovermode='closest',
xaxis=dict(
showgrid=True,
gridwidth=1,
gridcolor='#ECF0F1',
showline=True,
linewidth=2,
linecolor='#34495E'
),
yaxis=dict(
showgrid=True,
gridwidth=1,
gridcolor='#ECF0F1',
showline=True,
linewidth=2,
linecolor='#34495E'
)
)
# Enregistrer le template
pio.templates['chemistry'] = chemistry_template
# Utiliser le template
fig = px.scatter(df_mol, x='MW', y='LogP', color='Activity',
title='Graphique avec template chimie',
template='chemistry')
fig.show()
# Définir comme template par défaut
pio.templates.default = 'chemistry'
Comparaison Seaborn vs Plotly
| Aspect | Seaborn | Plotly Express |
|---|---|---|
| Interactivité | Statique | Interactive (zoom, hover, etc.) |
| Rapidité | Rapide pour exploration | Plus lent au rendu |
| Qualité publication | Excellente | Bonne (nécessite export) |
| Courbe d’apprentissage | Douce | Modérée |
| 3D | Non natif | Natif et excellent |
| Animations | Non | Oui |
| Intégration web | Via export | Natif HTML |
| Customisation | Matplotlib sous-jacent | API propre |
Dashboarding
[[Dashboarding]]
Références
Support Le Wagon : ![[Dashboarding.pdf]]
Dash
Documentation :
Community :