Notions de base
Somme et produits
Notation de somme (Σ)
-
Forme générale : \(\sum_{i=1}^{N} x_i\)
signifie « on additionne les termes $x_i$ pour $i$ allant de 1 à $N$. »
Correspondance en code :
total = 0
for i in 1..N:
total += x[i]
Notation de produit (Π)
- Forme générale : \(\prod_{i=1}^{N} x_i\) signifie « on multiplie les termes $x_i$ pour $i$ allant de 1 à $N$. »
Correspondance en code :
product = 1
for i in 1..N:
product *= x[i]
Utilisation courante : Utile dans les probabilités pour les probabilités conjointes. Souvent, on fait la transformation logarithmique : \(\log \prod_{i} x_i = \sum_{i} \log x_i\) Cela aide à éviter des erreurs de calcul avec des nombres très petits.
Notations spéciales
“x barre” = moyenne de la somme ^y = predicted y values
Résumé
| Notation | Signification | Exemple |
|---|---|---|
| Σ | Somme de plusieurs termes | $\sum_{i=1}^N x_i = x_1 + \cdots + x_N$ |
| Π | Produit de plusieurs termes | $\prod_{i=1}^N x_i = x_1 \cdots x_N$ |
| log + Σ | Produit → somme logarithmique | $\log\prod_{i=1}^N x_i = \sum_{i=1}^N \log x_i$ |
Vecteurs et index
Pour x = (3, 6, 29, 4, 7) et xi Alors x3 = 29
Logique mathématique
1. Définitions
- Logique : raisonnement appliqué aux mathématiques (preuves, vérité).
- Énoncé : phrase pouvant être vraie ou fausse.
- Énoncé simple vs composé :
- Simple : pas décomposable (ex. « 15 est impair »).
- Composé : combinaisons d’énoncés simples via connecteurs.
2. Connecteurs logiques fondamentaux
| Connecteur | Nom | Symbole | Interprétation |
|---|---|---|---|
| ∧ | Conjonction | ET | vrai si les deux sont vrais |
| ∨ | Disjonction | OU | vrai si au moins un est vrai |
| ∼ | Négation | NON | inverse la valeur de vérité |
Tables de vérité :
- A ∧ B : vrai uniquement si A et B vrais. :contentReference[oaicite:1]{index=1}
- A ∨ B : faux uniquement si A et B sont tous deux faux. :contentReference[oaicite:2]{index=2}
- ∼A : vrai si A est faux, et inversement. :contentReference[oaicite:3]{index=3}
3. Propriétés des négations (lois de De Morgan)
- ∼(p ∧ q) ≡ (∼p ∨ ∼q)
- ∼(p ∨ q) ≡ (∼p ∧ ∼q) :contentReference[oaicite:4]{index=4}
4. Implication et biconditionnelle
- Implication (p ⇒ q) : fausse uniquement si p est vrai et q faux. :contentReference[oaicite:5]{index=5}
- Contraposée : ∼q ⇒ ∼p
- Converse : q ⇒ p
- Biconditionnelle (p ⇔ q) : vrai si p et q ont la même valeur de vérité. :contentReference[oaicite:6]{index=6}
5. Tautologies et contradictions
- Tautologie : toujours vraie (ex. p ∨ ∼p ; De Morgan).
- Contradiction : toujours fausse. :contentReference[oaicite:7]{index=7}
6. Champs de la logique mathématique
- Théorie des ensembles
- Théorie des modèles
- Théorie de la récursion (calculabilité)
- Théorie de la preuve :contentReference[oaicite:8]{index=8}
Dérivées et Primitives
Les dérivées et les primitives sont deux faces complémentaires d’une même pièce en calcul intégral et différentiel, un peu comme le “aller” et le “retour” d’un chemin mathématique.
Dériver, c’est analyser le changement, tandis qu’intégrer, c’est accumuler ce changement pour reconstituer la totalité.
Ces deux concepts sont liés par le théorème fondamental du calcul, qui établit que dériver et intégrer sont des opérations inverses, ouvrant la porte à une multitude d’applications en physique, chimie, économie, et bien au-delà.
Dérivation
La dérivée d’une fonction exprime sa variation instantanée — c’est-à-dire comment la fonction change précisément à chaque instant. Imagine qu’on suit la trajectoire d’une voiture : la dérivée correspond à sa vitesse à un moment donné, la pente de la courbe qui décrit son déplacement. Mathématiquement, c’est la limite du taux de variation quand l’intervalle de temps devient infiniment petit. En ce sens, la dérivée donne une information locale, immédiate.
| Fonction f(x)f(x) | Dérivée f′(x)f’(x) | Remarques |
|---|---|---|
| cc (constante) | 00 | Toute constante dérivée est nulle |
| xnx^n (puissance) | nxn−1n x^{n-1} | n∈Rn \in \mathbb{R}, règle de puissance |
| exe^x | exe^x | Exponentielle, sa dérivée est elle-même |
| axa^x (exponentielle base aa) | axlnaa^x \ln a | a>0a > 0, a≠1a \neq 1 |
| lnx\ln x | 1x\frac{1}{x} | Défini pour x>0x > 0 |
| sinx\sin x | cosx\cos x | Fonction trigonométrique |
| cosx\cos x | −sinx-\sin x | |
| tanx\tan x | 1cos2x=1+tan2x\frac{1}{\cos^2 x} = 1 + \tan^2 x | Définie sauf pour x=π2+kπx = \frac{\pi}{2} + k\pi |
Primitives
la primitive (ou intégrale indéfinie) revient à retrouver la fonction d’origine à partir de sa dérivée. C’est comme si, connaissant seulement la vitesse, on cherchait à reconstituer le trajet parcouru. Cette opération consiste à additionner toutes les petites variations — on parle d’intégration — et permet donc de passer d’une connaissance locale (la pente) à une compréhension globale (la fonction elle-même). On peut se demander si cette dualité n’est pas au cœur de beaucoup de phénomènes scientifiques où l’on alterne entre mesures instantanées et compréhension d’ensemble.
| Fonction f(x)f(x) | Primitive F(x)F(x) | Remarques |
|---|---|---|
| 00 | cc (constante arbitraire) | La primitive d’une fonction nulle est une constante |
| xnx^n (avec n≠−1n \neq -1) | xn+1n+1+C\frac{x^{n+1}}{n+1} + C | Intégration par puissance |
| 1x\frac{1}{x} | ( \ln | x |
| exe^x | ex+Ce^x + C | Exponentielle |
| axa^x | axlna+C\frac{a^x}{\ln a} + C | a>0a > 0, a≠1a \neq 1 |
| sinx\sin x | −cosx+C-\cos x + C | |
| cosx\cos x | sinx+C\sin x + C | |
| 1cos2x\frac{1}{\cos^2 x} (ou sec2x\sec^2 x) | tanx+C\tan x + C |
Fonctions
Définition et propriétés
Définition : Une fonction est une relation qui associe à chaque élément d’un ensemble de départ (le domaine) exactement un élément d’un ensemble d’arrivée (le codomaine).
Notation mathématique : $f: X → Y$
Propriété fondamentale : À un input x correspond un unique output y = f(x)
import numpy as np
import matplotlib.pyplot as plt
def square_plus_one(x):
return x**2 + 1
x = np.linspace(-1, 2, 100) # x contains 100 values
y = square_plus_one(x) # y contains 100 values
plt.plot(x, y); # plot a line with 100 points
![[Pasted_image_20251104094419.png]]
Test graphique de fonction : Aucune ligne verticale ne peut intersecter la courbe deux fois. Cette propriété est toujours vraie : un input x est associé à un seul output y.
💡 En revanche, une ligne horizontale peut croiser la courbe plusieurs fois. Plusieurs inputs x peuvent avoir le même output y.
Fonction identité
La fonction identité est définie par : $f(x) = x$
![[Pasted_image_20251104094429.png]]
Propriété : Cette fonction ne transforme pas son input.
Usage en Machine Learning :
- Vérification que les prédictions correspondent aux valeurs réelles
- Comparaison baseline (si votre modèle ne fait pas mieux que l’identité, il est inutile !)
- Activation identity dans les réseaux de neurones (couches linéaires)
Fonctions linéaires
Définition : Une droite est définie par l’équation $f(x) = mx + b$
Paramètres :
- m : la pente (slope) - mesure l’inclinaison
- b : l’ordonnée à l’origine (intercept) - point d’intersection avec l’axe y
![[Pasted_image_20251104094541.png]]
Comment calculer ces paramètres ?
- Intercept : $b = f(0)$
- Pente : $m = \frac{f(x_B) - f(x_A)}{x_B - x_A}$
Propriété clé : Une fonction linéaire préserve la proportionnalité et l’addition :
- $f(x + y) = f(x) + f(y)$
- $f(αx) = αf(x)$
Fonctions non-linéaires
square_plus_one n’est pas linéaire. Voici d’autres exemples de fonctions non-linéaires courantes en data science :
![[Pasted_image_20251104094634.png]]
Fonctions importantes :
- Polynomiales : $f(x) = ax^n + bx^{n-1} + … + c$
- Exponentielles : $f(x) = e^x$ (croissance explosive)
- Logarithmiques : $f(x) = \ln(x)$ (croissance ralentie)
- Trigonométriques : $f(x) = \sin(x), \cos(x)$ (périodiques)
Fonction inverse
Définition : Une fonction inverse $f^{-1}$ est une fonction qui “annule” f.
Propriété : $f^{-1}(f(x)) = x$ et $f(f^{-1}(x)) = x$
![[Pasted_image_20251104094715.png]]
💡 Graphiquement, $f^{-1}$ est l’image miroir de $f$ à travers la droite $y = x$.
Condition d’existence : f possède une inverse si et seulement si f est une bijection.
💡 Test graphique : Aucune ligne horizontale ne peut intersecter la courbe plus d’une fois.
![[Pasted_image_20251104094800.png]]
Usage en ML :
- Normalisation/Dénormalisation : Transformation inverse pour récupérer les valeurs originales
- Fonctions d’activation : sigmoid et son inverse logit
- Encodage/Décodage : Autoencodeurs
Fonctions multivariées
Définition : Une fonction multivariée prend deux variables d’entrée ou plus.
Notation : $f: \mathbb{R}^2 → \mathbb{R}, \quad f(x_1, x_2) = 2x_1 - 3x_2 + 7$
import plotly.graph_objects as go
fun = lambda x, y: 2*x - 3*y + 7 # bivariate function
x, y = np.meshgrid(range(10), range(10)) # grid of x's and y's
z = fun(x, y) # z's
fig = go.Figure(go.Surface(x=x, y=y, z=z)); fig.show()
![[Pasted_image_20251104094850.png]]
Extension à n dimensions : En data science, vos fonctions prennent souvent des centaines ou milliers de variables en entrée !
Équations et systèmes
Équations à une variable
Définition : Une équation est une formule contenant une ou plusieurs variables inconnues.
Exemple simple : $2x = 4$
Types de solutions :
- Une solution : $2x = 4$ → $x = 2$
- Deux solutions : $x^2 = 4$ → $x = ±2$
- Infinité de solutions : $x = x$ (toujours vrai)
- Aucune solution : $x = x + 2$ (contradiction)
Systèmes d’équations
Définition : Un système d'équations est une collection de deux ou plusieurs équations impliquant le même ensemble de variables inconnues.
Solution : Ensemble de valeurs des inconnues qui satisfont toutes les contraintes.
[!example]- Le problème du père et de la fille 🤔 Énoncé :
- Un
pèreest 22 ans plus âgé que safille- Dans 10 ans, le
pèresera deux fois plus âgé que safilleCombien ont-ils d’années ?
Modélisation mathématique : Soit $y$ l’âge du père et $x$ l’âge de la fille.
\[\begin{cases} y = x + 22 \quad (1)\\ y + 10 = 2(x + 10) \quad (2) \end{cases}\]Simplification de (2) : $y = 2x + 10$
Résolution graphique :
![[Pasted_image_20251104095517.png]]
💡 La ligne bleue représente l’ensemble des $(x, y)$ satisfaisant l’équation (1) 💡 La ligne orange représente l’ensemble des $(x, y)$ satisfaisant l’équation (2)
Point d’intersection : Il existe un et un seul point qui satisfait les deux équations.
Méthode algébrique :
- Combiner (1) et (2) : $x + 22 = 2x + 10$
- Résoudre : $x = 12$
- Substituer dans (1) : $y = 12 + 22 = 34$
Réponse : La fille a 12 ans, le père a 34 ans.
Vecteurs
Définition géométrique
Dans un plan, un vecteur géométrique est défini par :
- Deux points (origine et extrémité)
- Ou par une
magnitude(longueur), unedirectionet unsens
Propriété : $\vec{AB} = \vec{AH} + \vec{HB}$ et $\vec{AB} = \vec{C}$
![[Pasted_image_20251104095644.png]]
Coordonnées et représentation
Si nous avons une origine $O$ et deux vecteurs unitaires $\vec{\imath}$ et $\vec{\jmath}$, tout vecteur est uniquement défini par deux coordonnées.
![[Pasted_image_20251104095727.png]]
Dualité fondamentale : Tout couple de nombres peut être compris comme :
- Un point dans un plan
- Un vecteur (déplacement depuis l’origine)
Notations
Convention d’écriture :
Un vecteur :
- Avec une flèche : $\vec{a}$
- En gras, italique, minuscule : $\mathbf{a}$
Forme matricielle : $\mathbf{a} = \begin{bmatrix} 1 \ 2 \end{bmatrix}$ ou $[1, 2]$
Les vecteurs unitaires : $\mathbf{i} = \begin{bmatrix} 1 \ 0 \end{bmatrix}$ et $\mathbf{j} = \begin{bmatrix} 0 \ 1 \end{bmatrix}$
Scalaire (par contraste) : non gras, italique, minuscule → $a$
Vecteurs en haute dimension
Extension naturelle :
- Vecteur $\mathbf{a} = \begin{bmatrix} 1 \ 2 \end{bmatrix}$ vit dans un espace 2D (un plan)
- Vecteur $\mathbf{u} = \begin{bmatrix} 1 \ 2 \ 3 \end{bmatrix}$ vit dans un espace 3D
- Vecteur $\mathbf{x} = \begin{bmatrix} x_1 \ x_2 \ \vdots \ x_n \end{bmatrix}$ vit dans un espace n-dimensionnel ! 🤩
Dualité conceptuelle : Un vecteur est à la fois :
- Une séquence de n nombres
- Un point dans un espace à n dimensions
Vecteurs en data science
Exemple concret : Dataset d’appartements avec 3 caractéristiques numériques.
![[Pasted_image_20251104101432.png]]
Représentation : Chaque appartement (ligne) est représenté par :
- Un
vecteurde taille 3 - Un
pointdans un espace 3D
L’ensemble du dataset forme un nuage de points dans cet espace 3D !
Et s’il y a plus de 3 caractéristiques ?
![[Pasted_image_20251104101449.png]]
On peut se demander si cette capacité à représenter des données comme des points dans des espaces à haute dimension ne constitue pas l’une des intuitions les plus puissantes de la data science ?
Programmation basique avec les vecteurs
Création de vecteurs :
import numpy as np
u = np.array([1, 2, 3]) # shape (3,)
u_row = np.array([[1, 2, 4]]) # shape (1, 3) (vecteur ligne)
u_column = np.array([[1], [2], [3]]) # shape (3, 1) (vecteur colonne)
Addition de vecteurs :
v = np.array([4, 5, 6])
u + v
array([5, 7, 9])
Propriété : L’addition est commutative et associative.
Multiplication par un scalaire (⚠️ ≠ produit scalaire ⚠️) :
2 * u
array([2, 4, 6])
Interprétation géométrique : Multiplie la longueur du vecteur par le scalaire.
Distance et norme
Norme L2 (euclidienne)
Définition : La norme L2 d’un vecteur $\mathbf{a}$, notée $ |
\mathbf{a} | _2$, est la distance de l’origine $O(0,0)$ au point $A(a_x, a_y)$. |
Distance entre deux vecteurs : La distance $L2$ entre $\mathbf{a}$ et $\mathbf{b}$ est la norme du vecteur différence :
\[AB = ||\mathbf{b} - \mathbf{a}||_2\]![[Pasted_image_20251104101740.png]]
Formule (théorème de Pythagore) :
\[AB = \sqrt{(b_x - a_x)^2 + (b_y - a_y)^2}\] \[OA = ||\mathbf{a}||_2 = \sqrt{a_x^2 + a_y^2}\]Extension à n dimensions :
\[OA = ||\mathbf{a}||_2 = \sqrt{a_1^2 + a_2^2 + ... + a_n^2} = \sqrt{\sum_{i=1}^{n} a_i^2}\] \[AB = ||\mathbf{b} - \mathbf{a}||_2 = \sqrt{\sum_{i=1}^{n} (b_i - a_i)^2}\]Norme L1 (Manhattan)
Définition : La distance L1 (aussi appelée Manhattan ou cityblock) :
Interprétation : Distance parcourue en se déplaçant le long des axes (comme dans une ville quadrillée).
Exemple de calcul :
a = np.array([1, 2, 3, 4])
b = np.array([5, 5, 5, 5]) # Nous vivons tous deux dans un espace 4D !
# Différence
b - a
array([4, 3, 2, 1])
# Carré des différences (b - a)**2array([16, 9, 4, 1])
# Distance L2 np.sqrt(np.sum((b - a)**2))5.477225575051661
Produit scalaire
Définition : Le produit scalaire (dot product) prend 2 vecteurs (de même taille) et retourne un scalaire.
Notation : $\mathbf{a} \cdot \mathbf{b}$
Propriétés géométriques :
-
Maximal si les vecteurs pointent dans la même direction : \(\mathbf{a} \cdot \mathbf{b} = ||\mathbf{a}||_2 \times ||\mathbf{b}||_2\)
-
Nul si les vecteurs sont orthogonaux (perpendiculaires) : \(\mathbf{a} \cdot \mathbf{b} = 0\)
![[Pasted_image_20251104103057.png]]
Formule algébrique :
\[\mathbf{a} \cdot \mathbf{b} = a_1 b_1 + a_2 b_2 + ... + a_n b_n = \sum_{i=1}^{n} a_i b_i\]Relation avec l’angle :
\[\mathbf{a} \cdot \mathbf{b} = ||\mathbf{a}|| \times ||\mathbf{b}|| \times \cos \theta\]💡 $\cos \theta$, aussi appelé similarité cosinus, est très utilisé en NLP (traitement du langage naturel) pour mesurer la similarité entre vecteurs de mots.
Calcul manuel :
\[\begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix} \cdot \begin{bmatrix} 4 \\ 5 \\ 6 \end{bmatrix} = 1 \times 4 + 2 \times 5 + 3 \times 6 = 4 + 10 + 18 = 32\]![[Pasted_image_20251104104117.png]]
Avec NumPy :
u = np.array([1, 2, 3])
v = np.array([4, 5, 6])
np.dot(u, v) # ou...
u.dot(v) # ou...
u @ v # (opérateur @ depuis Python 3.5)
Matrices
Définition et notation
Définition : Une matrice est un tableau bidimensionnel de scalaires.
Notation : Lettre majuscule, gras, italique
Exemple :
\[\mathbf{A} = \begin{bmatrix} a_{1,1} & a_{1,2} & \cdots & a_{1,n} \\ a_{2,1} & a_{2,2} & \cdots & a_{2,n} \\ a_{3,1} & a_{3,2} & \cdots & a_{3,n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m,1} & a_{m,2} & \cdots & a_{m,n} \end{bmatrix}\]Dimensions : $\mathbf{A}$ est une matrice avec $m$ lignes et $n$ colonnes (forme $m \times n$)
Interprétations multiples :
Une matrice peut être vue comme :
- Une collection de
vecteurs colonnesempilés horizontalement - Une collection de
vecteurs lignesempilés verticalement - N’importe quel tableau numérique (DataFrame pandas, etc.)
- Une image en niveaux de gris (pixels = intensités)
Opérations basiques
Transposition
Définition : La transposée de la matrice $\mathbf{A}$ est notée $\mathbf{A}^T$
Effet : Les lignes deviennent les colonnes et vice-versa.
| 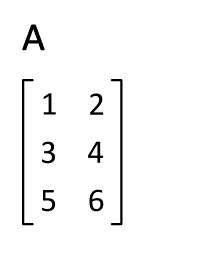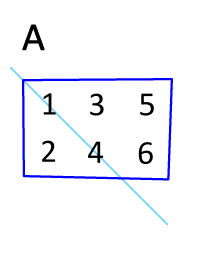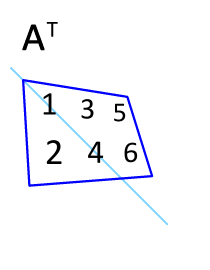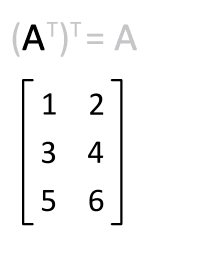 |
Propriété : $(\mathbf{A}^T)^T = \mathbf{A}$
Addition de matrices
Condition : $\mathbf{A}$ et $\mathbf{B}$ doivent avoir la même forme.
Opération : Addition élément par élément.
\[\begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} + \begin{bmatrix} 1 & 4 & 2 \\ 5 & 3 & 6 \end{bmatrix} = \begin{bmatrix} 2 & 6 & 5 \\ 9 & 8 & 12 \end{bmatrix}\]Multiplication par un scalaire
Opération : Chaque élément de $\mathbf{A}$ est multiplié par $\lambda$.
\[3 \cdot \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} = \begin{bmatrix} 3 & 6 & 9 \\ 12 & 15 & 18 \end{bmatrix}\]Avec NumPy :
A = np.array([[1, 2, 3], [4, 5, 6]])
A.shape # (n_rows, n_columns) → (2, 3)
A.T # transpose de A
A + B # addition
3 * A # multiplication scalaire
Multiplication matricielle
Matrice • Vecteur
Exemple :
\[\begin{bmatrix} 1 & 2 & 3 \\ 0 & 1 & 2 \end{bmatrix} \cdot \begin{bmatrix} 4 \\ 5 \\ 6 \end{bmatrix} = ?\]Condition : Le nombre de colonnes de la matrice doit égaler la taille du vecteur colonne.
![[Pasted_image_20251104104631.png]]
Résultat : Vecteur de taille égale au nombre de lignes de la matrice.
Calcul :
- Ligne 1 : $1 \times 4 + 2 \times 5 + 3 \times 6 = 32$
- Ligne 2 : $0 \times 4 + 1 \times 5 + 2 \times 6 = 17$
Résultat : $\begin{bmatrix} 32 \ 17 \end{bmatrix}$
Matrice • Matrice
Exemple :
\[\begin{bmatrix} 1 & 2 & 3 \\ 0 & 1 & 2 \end{bmatrix} \cdot \begin{bmatrix} 4 & 1 & -1 & 0 \\ 5 & 0 & 3 & 2 \\ 6 & 4 & 0 & 1 \end{bmatrix} = ?\]Condition : Le nombre de colonnes de la matrice de gauche doit égaler le nombre de lignes de la matrice de droite.
![[Pasted_image_20251104104704.png]]
Avec NumPy :
A = np.array([[1, 2, 3],
[0, 1, 2]])
B = np.array([[4, 1, -1, 0],
[5, 0, 3, 2],
[6, 4, 0, 1]])
# Matrice • Matrice
np.matmul(A, B) # ou...
A @ B
array([[32, 13, 5, 7], [17, 8, 3, 4]])
Propriétés de la multiplication matricielle
Propriétés vérifiées :
✅ Associative : $(AB) \cdot C = A \cdot (BC)$
✅ Distributive : $A \cdot (B + C) = AB + AC$
Propriété NON vérifiée :
❌ PAS Commutative : $AB \neq BA$
⚠️ L’ordre est crucial en multiplication matricielle !
Matrice identité
Définition : Une matrice identité est une matrice carrée avec une diagonal de uns et des zéros partout ailleurs.
Propriété : Si les dimensions sont compatibles :
\[\mathbf{A} \cdot \mathbf{I} = \mathbf{A} \quad \text{et} \quad \mathbf{I} \cdot \mathbf{A} = \mathbf{A}\]Analogie : Équivalent du nombre 1 pour la multiplication.
NumPy : numpy.eye(n) crée une matrice identité $n \times n$
Matrice inverse
Définition : L’inverse d'une matrice $\mathbf{A}$ est une matrice notée $\mathbf{A}^{-1}$ qui satisfait :
Conditions d’existence :
⚠️ Seules les matrices carrées peuvent avoir une inverse…
⚠️ … et certaines matrices carrées n’ont pas d’inverse !
NumPy : numpy.linalg.inv(A)
Déterminant
Définition : Le déterminant d’une matrice carrée est un scalaire qui caractérise certaines propriétés de la matrice.
Propriété clé : Une matrice carrée est inversible si et seulement si son déterminant n’est pas 0.
\[\det(\mathbf{A}) \neq 0 \quad \Leftrightarrow \quad \mathbf{A}^{-1} \text{ existe}\]Interprétation géométrique : Le déterminant mesure le “facteur de mise à l’échelle” d’une transformation linéaire.
👉 Vidéo recommandée : Linear transformations and matrices par 3blue1brown 🥰
NumPy : numpy.linalg.det(A)
Multiplication matricielle et data science
[!NOTE] Vecteur • Vecteur Expression mathématique :
\[y = a_1 x_1 + a_2 x_2 + ... + a_n x_n\]Équivalent vectoriel : $y = \mathbf{a} \cdot \mathbf{x}$
Application : Estimer le
prixd’un appartement ($y$) par une combinaison linéaire (poids = $\mathbf{a}$) descaractéristiques($\mathbf{x}$).![[Pasted_image_20251104105719.png]]
[!NOTE] Vecteur • Matrice Système d’équations :
\[\begin{cases} y_1 = a_1 x_{1,1} + a_2 x_{1,2} + ... + a_n x_{1,n} \\ y_2 = a_1 x_{2,1} + a_2 x_{2,2} + ... + a_n x_{2,n} \\ \vdots \\ y_m = a_1 x_{m,1} + a_2 x_{m,2} + ... + a_n x_{m,n} \end{cases}\]Équivalent matriciel : $\mathbf{y} = \mathbf{a} \cdot \mathbf{X}$
Application : Estimer le
prixde plusieurs appartements simultanément ! 🔥🔥![[Pasted_image_20251104105747.png]]
[!NOTE] Matrice • Matrice Expression : $\mathbf{Y} = \mathbf{A} \cdot \mathbf{X}$
Application : Effectuer plusieurs opérations sur plusieurs appartements ! 🔥🔥🔥
![[Pasted_image_20251104105805.png]]
Avantages de la notation matricielle :
- Concision : Une ligne de code au lieu de boucles imbriquées
- Efficacité : Optimisations BLAS/LAPACK sous-jacentes
- Clarté : Correspond à la notation mathématique
Résolution de systèmes linéaires
Problème du père et de la fille (revisité) :
\[\begin{cases} 1 \cdot x_1 + (-1) \cdot x_2 = 22 \\ 1 \cdot x_1 + (-2) \cdot x_2 = 10 \end{cases} \quad \Leftrightarrow \quad \mathbf{A} \cdot \mathbf{x} = \mathbf{b}\]Où :
\[\mathbf{A} = \begin{bmatrix} 1 & -1 \\ 1 & -2 \end{bmatrix}, \quad \mathbf{x} = \begin{bmatrix} x_1 \\ x_2 \end{bmatrix}, \quad \mathbf{b} = \begin{bmatrix} 22 \\ 10 \end{bmatrix}\]Résolution :
-
Multiplier les deux côtés par $\mathbf{A}^{-1}$ à gauche : \(\mathbf{A}^{-1} \cdot (\mathbf{A} \cdot \mathbf{x}) = \mathbf{A}^{-1} \cdot \mathbf{b}\)
-
Utiliser l’associativité : \(\mathbf{A}^{-1} \cdot (\mathbf{A} \cdot \mathbf{x}) = (\mathbf{A}^{-1} \cdot \mathbf{A}) \cdot \mathbf{x} = \mathbf{I}_2 \cdot \mathbf{x} = \mathbf{x}\)
-
Finalement : \(\mathbf{x} = \mathbf{A}^{-1} \cdot \mathbf{b}\)
Avec NumPy :
A = np.array([[1, -1], [1, -2]])
b = np.array([[22], [10]])
np.linalg.inv(A) @ b
array([[34.], [12.]])
Réponse : Le père a 34 ans, la fille a 12 ans.
Complexité computationnelle
Question : Comment NumPy calcule-t-il $\mathbf{A}^{-1}$ ?
Algorithme : Élimination de Gauss
Complexité : $O(n^3)$
Cette complexité peut être améliorée mais on ne peut pas descendre en dessous de $O(n^{2.3})$ actuellement.
Notation “Big O”
Définition : La notation $O(f(n))$ décrit comment le temps d’exécution d’un algorithme croît avec la taille $n$ des données.
![[Pasted_image_20251104110905.png]]
Exemples de complexité :
- O(1) : Accéder au premier élément d’une liste
- O(log n) : Recherche dichotomique dans une liste triée (diviser pour régner)
- O(n) : Parcourir tous les éléments d’une liste (boucle simple)
- O(n log n) : Tri efficace (quicksort, mergesort)
- O(n²) : Boucle imbriquée (double
for) - O(2ⁿ) : Cassage de mot de passe (force brute), fonctions récursives naïves
📚 Ressource : Understanding time complexity with Python examples
Innovation récente : AlphaT ensor de DeepMind découvre de nouveaux algorithmes de multiplication matricielle !
Changement de base et projection
Concept avancé : La multiplication matricielle peut représenter :
- Un changement de base
- Une projection
Interprétation géométrique :
\[\begin{bmatrix} a & c \\ b & d \end{bmatrix} \cdot \begin{bmatrix} 1 \\ 0 \end{bmatrix} = \begin{bmatrix} a \\ b \end{bmatrix}\] \[\begin{bmatrix} a & c \\ b & d \end{bmatrix} \cdot \begin{bmatrix} 0 \\ 1 \end{bmatrix} = \begin{bmatrix} c \\ d \end{bmatrix}\]Le vecteur $\mathbf{i}$ devient $\begin{bmatrix} a \ b \end{bmatrix}$ et le vecteur $\mathbf{j}$ devient $\begin{bmatrix} c \ d \end{bmatrix}$.
👉 Vidéo recommandée : Linear transformations and matrices par 3blue1brown 🥰
Applications en ML :
- PCA (Principal Component Analysis) : Changement de base vers les composantes principales
- t-SNE : Projection non-linéaire pour visualisation
- Réseaux de neurones : Chaque couche = transformation linéaire + non-linéarité
Conclusion
On peut se demander si ces concepts mathématiques - fonctions, vecteurs, matrices - ne constituent pas le langage universel qui unifie toute la data science ?
Récapitulatif des concepts clés
Fonctions :
- Relation input → output
- Linéaires vs non-linéaires
- Inverses et compositions
Vecteurs :
- Représentation de points en haute dimension
- Normes (L1, L2) pour mesurer distances
- Produit scalaire pour mesurer similarités
Matrices :
- Collections de vecteurs
- Transformations linéaires
- Résolution de systèmes d’équations
Applications directes en data science
| Concept | Application ML/DS |
|---|---|
| Produit scalaire | Similarité cosinus, attention mechanisms |
| Norme L2 | Distance euclidienne, régularisation |
| Multiplication matricielle | Forward pass dans les réseaux de neurones |
| Matrice inverse | Régression linéaire (méthode des moindres carrés) |
| Déterminant | Covariance, test de colinéarité |
| Transposition | Backpropagation, calcul de gradients |
Pour aller plus loin
Ressources recommandées :
- 📺 3Blue1Brown - Essence of Linear Algebra
- 📚 Introduction to Linear Algebra - Gilbert Strang
- 💻 NumPy for Scientific Computing
Prochaines étapes :
- Calcul différentiel et optimisation
- Algèbre linéaire avancée (valeurs propres, décomposition SVD)
- Statistiques et probabilités
La maîtrise de ces fondamentaux mathématiques ne garantit pas le succès en data science, mais leur absence garantit presque les limitations. Investir dans cette compréhension, c’est investir dans votre capacité à innover et résoudre des problèmes complexes ! 🚀
Des questions sur un concept particulier ou envie d’approfondir une application spécifique en chimie computationnelle ? 🔬 “””